This article demystifies the ML learning modeling process under the prism of statistics. We will understand how our assumptions on the data enable us to create meaningful optimization problems. In fact, we will derive commonly used criteria such as cross-entropy in classification and mean square error in regression. Finally, I am trying to answer an interview question that I encountered: What would happen if we use MSE on binary classification?
Likelihood VS probability and probability density
To begin, let's start with a fundamental question: what is the difference between likelihood and probability? The data x are connected to the possible models θ by means of a probability P(x,θ) or a probability density function (pdf) p(x,θ).
In short, A pdf gives the probabilities of occurrence of different possible values. The pdf describes the infinitely small probability of any given value. We'll stick with the pdf notation here. For any given set of parameters θ, p(x,θ) is intended to be the probability density function of x.
The likelihood p(x,θ) is defined as the joint density of the observed data as a function of model parameters. That means, for any given x, p(x=fixed,θ) can be viewed as a function of θ. Thus, the likelihood function is a function of the parameters θ only, with the data held as a fixed constant.
Notations
We will consider the case were we are dealt with a set X of m data instances X={x(1),..,x(m)} that follow the empirical training data distribution pdatatrain(x)=pdata(x), which is a good and representative sample of the unknown and broader data distribution pdatareal(x).
The Independent and identically distributed assumption
This brings us to the most fundamental assumption of ML: Independent and Identically Distributed (IID) data (random variables). Statistical independence means that for random variables A and B, the joint distribution PA,B(a,b) factors into the product of their marginal distribution functions PA,B(a,b)=PA(a)PB(b). That's how sums multi-variable joint distributions are turned into products. Note that the product can be turned into a sum by taking the log∏x=∑logx. Since log(x) is monotonic, it's not changing the optimization problem.
Our estimator (model) will have some learnable parameters θ that make another probability distribution pmodel(x,θ). Ideally, pmodel(x,θ)≈pdata(x).
The essence of ML is to pick a good initial model that exploits the assumptions and the structure of the data. Less literally, a model with a decent inductive bias. As the parameters are iteratively optimized, pmodel(x,θ) gets closer to pdata(x).
In neural networks, because the iterations happen in a mini-batch fashion instead of the whole dataset, m will be the mini-batch size.
Maximum Likelihood Estimation (MLE)
Maximum Likelihood Estimation (MLE) is simply a common principled method with which we can derive good estimators, hence, picking θ such that it fits the data.
To disentangle this concept, let's observe the formula in the most intuitive form:
θMLE=paramsargmaxpmodel(output∣inputs,params)
The optimization problem is maximizing the likelihood of the given data. Outputs are the conditions in the probability world. Unconditional MLE means we have no conditioning on the outputs, so no labels.
In a supervised ML context, the condition would simply be the data labels.
θML=θargmaxi=1∑mlogpmodel(y(i)∣x(i),θ)
Quantifying distribution closeness: KL-div
One way to interpret MLE is to view it as minimizing the "closeness" between the training data distribution pdata(x) and the model distribution pmodel(x,θ). The best way to quantify this "closeness" between distributions is the KL divergence, defined as:
where E denotes the expectation over all possible training data. In general, the expected value E is a weighted average of all possible outcomes. We will replace the expectation with a sum, whilst multiplying each term with its possible "weight" of happening, that is pdata.
Notice that I intentionally avoided using the term distance. Why? Because a distance function is defined to be symmetric. KL-div, on the other hand, is asymmetric meaning DKL(pdata∥pmodel)=DKL(pmodel∥pdata).
Intuitively, you can think of pdata as a static "source" of information that sends (passes) batches of data to pmodel, the "receiver". Since information is passed one way only, that is from pdata to pmodel, it would make no sense to calculate the distance with pmodel as the reference source. You can practically observe this nonsense by swapping the target and the model prediction in the cross-entropy or KL-div loss function in your code.
By replacing the expectation E with our lovely sum:
The optimal parameters θ will, in principle, be the same. Even though the optimization landscape would be different (as defined by the objective functions), maximizing the likelihood is equivalent to minimizing the KL divergence. In this case, the entropy of the data H(pdata) will shift the landscape, while a scalar multiplication would scale the optimization landscape. Sometimes I find it helpful to imagine the landscape as descending a mountain. Practically, both are framed as minimizing an objective cost function.
From the statistical point of view, it's more of bringing the distributions close so KL-div. From the aspect of information theory, cross-entropy might make more sense to you.
MLE in Linear regression
Let's consider linear regression. Imagine that each single prediction y^ produces a "conditional" distribution pmodel(y^∣x), given a sufficiently large train set. The goal of the learning algorithm is again to match the distribution pdata(y∣x).
Now we need an assumption. We hypothesize the neural network or any estimator f as y^=f(x,θ). The estimator approximates the mean of the normal distribution (N(μ,σ)) the we choose to parametrize pdata. Specifically, in the simplest case of linear regression we have μ=θTx. We also assume a fixed standard deviation σ of the normal distribution. These assumptions immediately causes MLE to become Mean Squared Error (MSE) optimization. Let's see how.
This is in line with our definition of conditional MLE:
θML=θargmaxi=1∑mlogpmodel(y(i)∣x(i),θ)
Broadly speaking, MLE can be applied to most (supervised) learning problems,
by specifying a parametric family of (conditional) probability distributions.
Another way to achieve this in a binary classification problem would be to take the scalar output y of the linear layer and pass it from a sigmoid function. The output will be in the range [0,1] and we define this as the probability of p(y=1∣x,θ).
p(y=1∣x,θ)=σ(θTx)=sigmoid(θTx)∈[0,1]
Consequently, p(y=0∣x,θ)=1−p(y=1∣x,θ). In this case binary-cross entropy is practically used. No closed form solution exist here, one can approximate it with gradient descend. For reference, this approach is surprisingly known as ""logistic regression".
Bonus: What would happen if we use MSE on binary classification?
So far I presented the basics. This is a bonus question that I was asked during an ML interview: What if we use MSE on binary classification?
One intuitive way to guess what's happening without diving into the math is this one: in the beginning of training the network will output something very close to 0.5, which gives roughly the same signal for both classes. Below is a more principled method proposed after the initial release of the article by Jonas Maison.
Let's assume that we have a simple neural network with weights θ such as z=θ⊺x, and outputs y^=σ(z) with a sigmoid activation.
∂θ∂L=∂y^∂L∂z∂y^∂θ∂z
MSE Loss
L(y,y^)=21(y−y^)2
∂θ∂L=−(y−y^)σ(z)(1−σ(z))x
∂θ∂L=−(y−y^)y^(1−y^)x
σ(z)(1−σ(z)) makes the gradient vanish if σ(z) is close to 0 or 1. Thus, the neural net can't train.
Binary Cross Entropy (BCE) Loss
L(y,y^)=−ylog(y^)−(1−y)log(1−y^)
For y=0:
∂θ∂L=1−y^1−yσ(z)(1−σ(z))x
∂θ∂L=1−y^1−yy^(1−y^)x
∂θ∂L=(1−y)(y^)x
∂θ∂L=y^x
If the network is right, y^=0, the gradient is null.
For y=1:
∂θ∂L=−y^yσ(z)(1−σ(z))x
∂θ∂L=−y^yy^(1−y^)x
∂θ∂L=−y(1−y^)x
∂θ∂L=−(1−y^)x
If the network is right, y^=1, the gradient is null.
Conclusion and References
This short analysis explains why we blindly choose our objective functions to minimize such as cross-entropy. MLE is a principled way to define an optimization problem and I find it a common discussion topic to back up design choices during interviews.
* Disclosure: Please note that some of the links above might be affiliate links, and at no additional cost to you, we will earn a commission if you decide to make a purchase after clicking through.
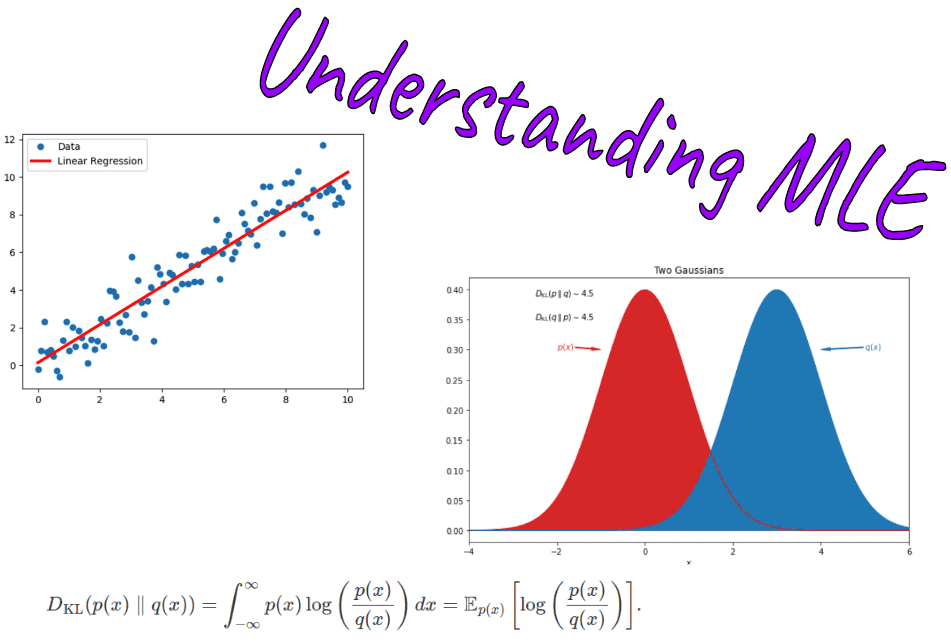
 Illustration of the relative entropy for two normal distributions. The typical asymmetry is clearly visible. By Mundhenk at English Wikipedia, CC BY-SA 3.0
Illustration of the relative entropy for two normal distributions. The typical asymmetry is clearly visible. By Mundhenk at English Wikipedia, CC BY-SA 3.0 

