
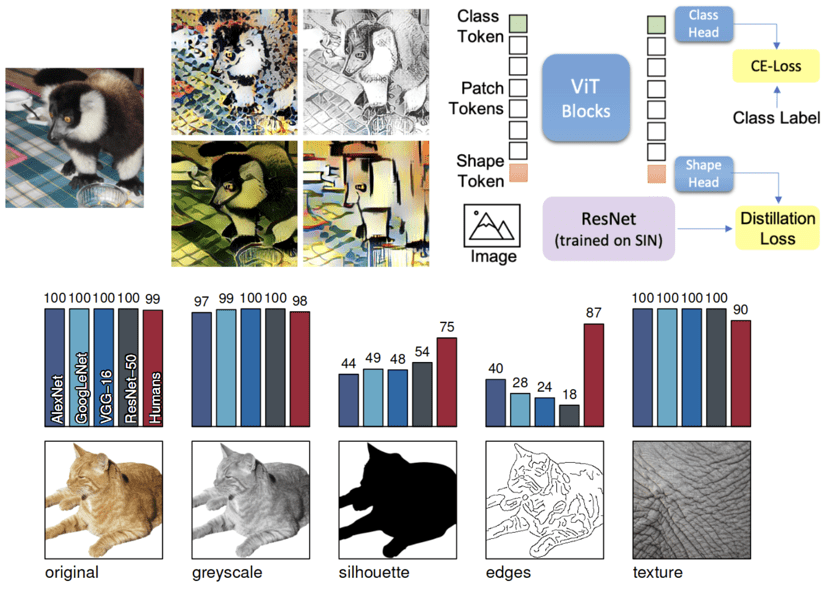
Understanding Vision Transformers (ViTs): Hidden properties, insights, and robustness of their representations
We study the learned visual representations of CNNs and ViTs, such as texture bias, how to learn good representations, the robustness of pretrained models, and finally properties that emerge from trained ViTs.
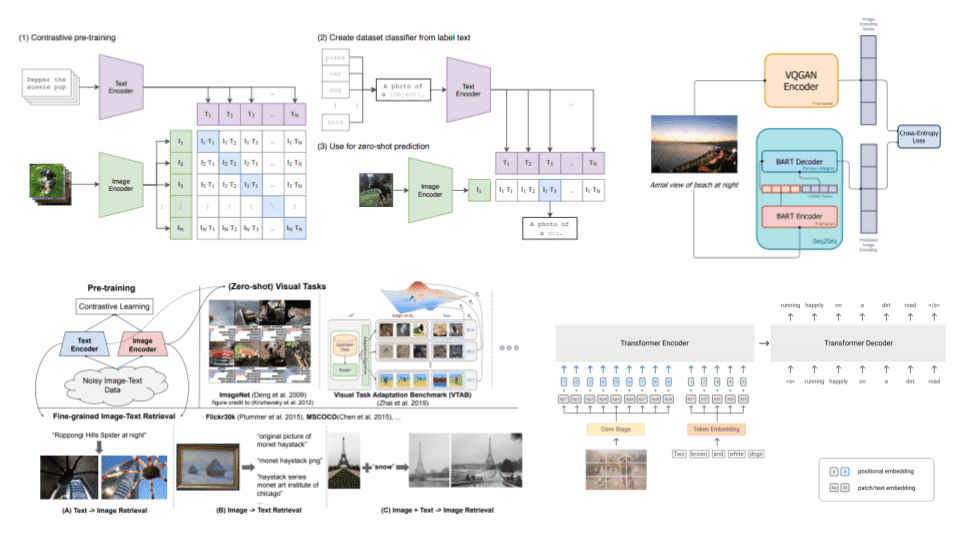
Vision Language models: towards multi-modal deep learning
A review of state of the art vision-language models such as CLIP, DALLE, ALIGN and SimVL
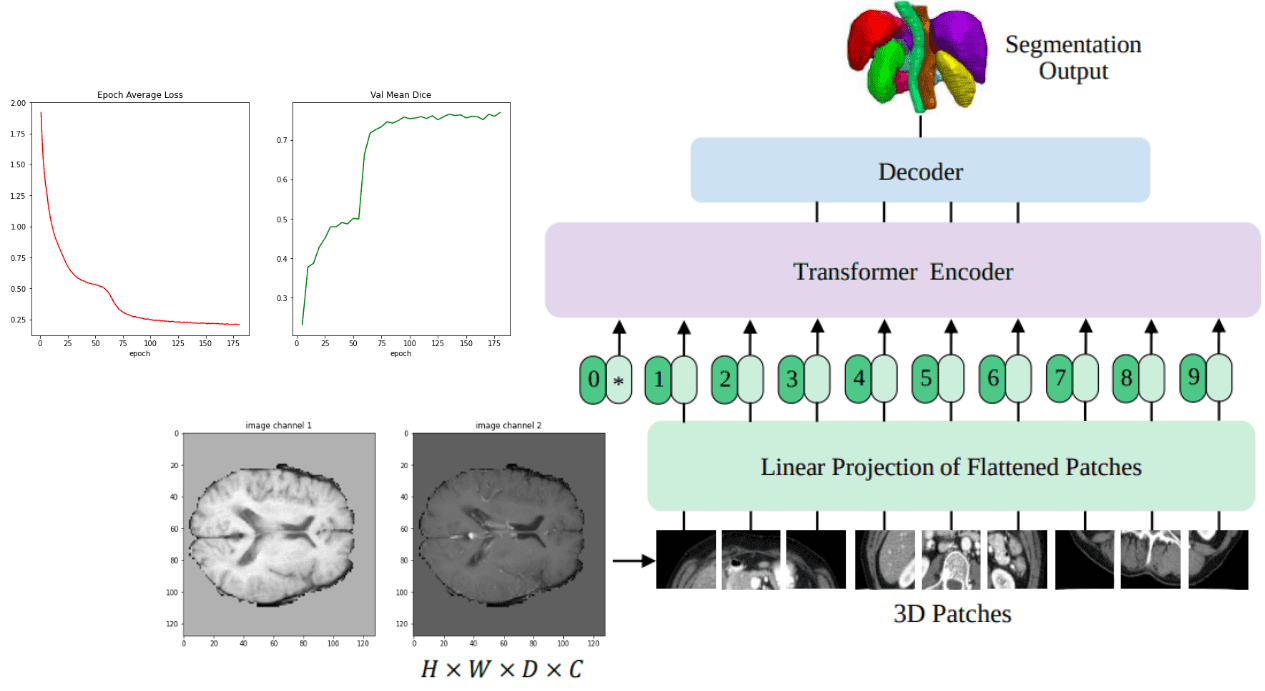
3D Medical image segmentation with transformers tutorial
Implement a UNETR to perform 3D medical image segmentation on the BRATS dataset
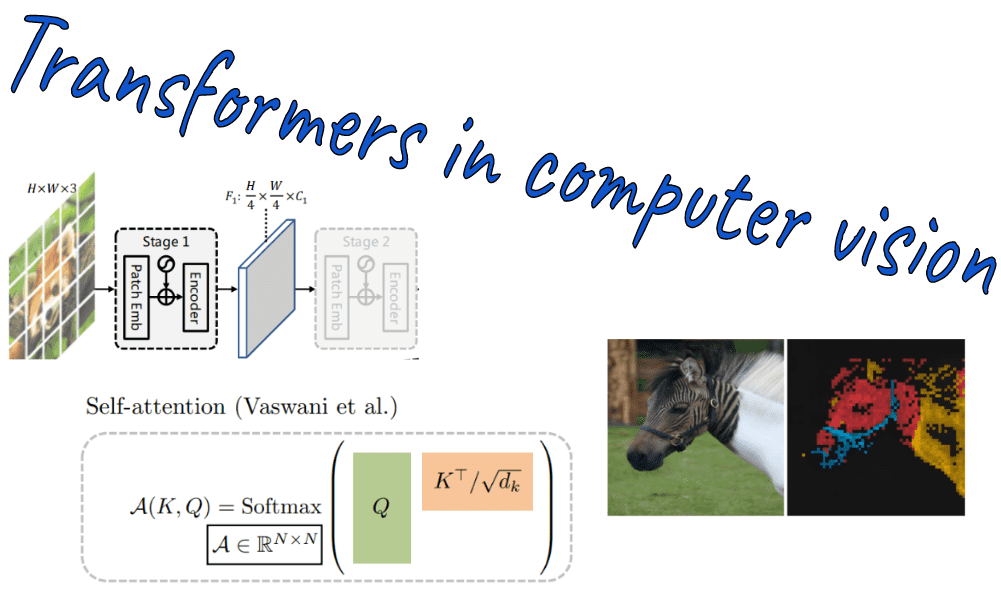
Transformers in computer vision: ViT architectures, tips, tricks and improvements
Learn all there is to know about transformer architectures in computer vision, aka ViT.
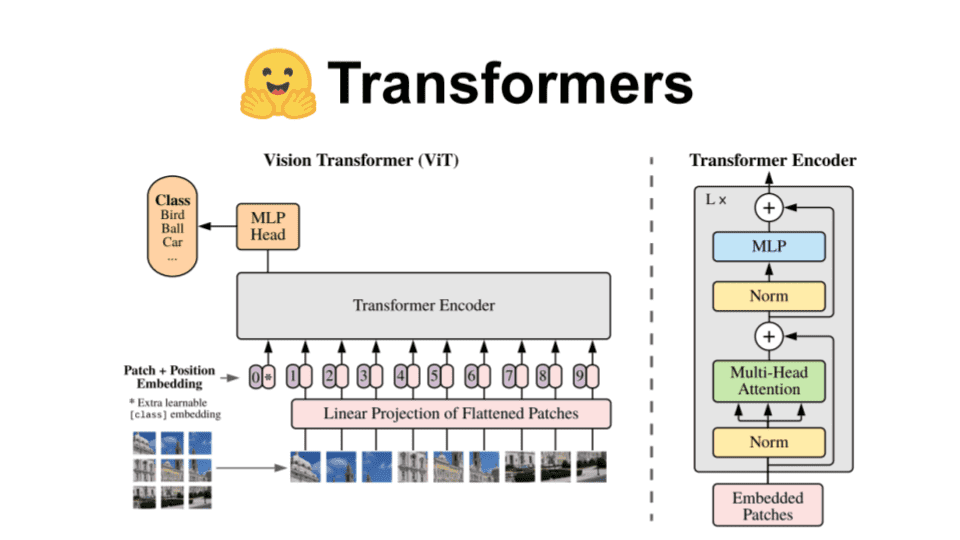
A complete Hugging Face tutorial: how to build and train a vision transformer
Learn about the Hugging Face ecosystem with a hands-on tutorial on the datasets and transformers library. Explore how to fine tune a Vision Transformer (ViT)

Why multi-head self attention works: math, intuitions and 10+1 hidden insights
Learn everything there is to know about the attention mechanisms of the infamous transformer, through 10+1 hidden insights and observations
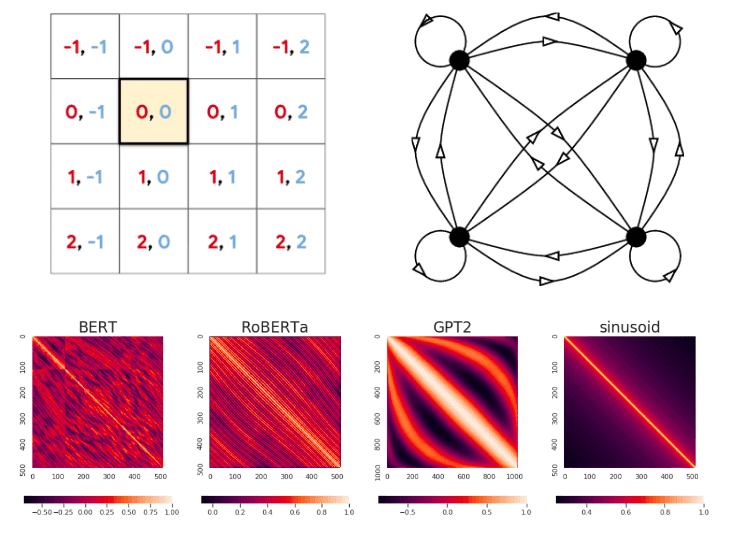
How Positional Embeddings work in Self-Attention (code in Pytorch)
Understand how positional embeddings emerged and how we use the inside self-attention to model highly structured data such as images
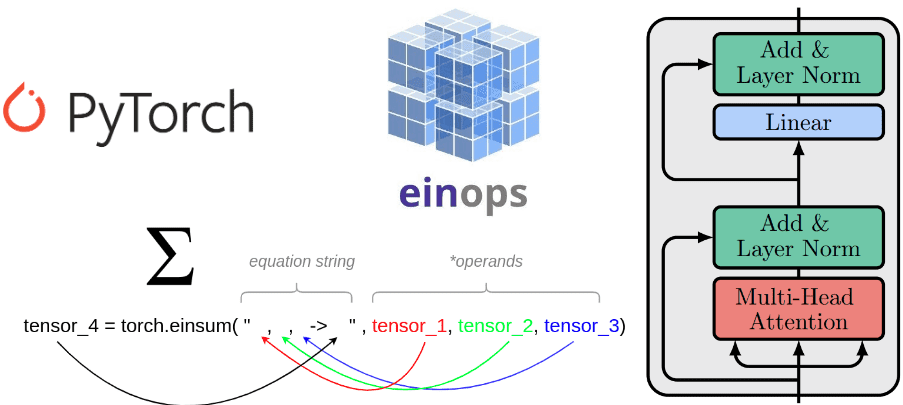
Understanding einsum for Deep learning: implement a transformer with multi-head self-attention from scratch
Learn about the einsum notation and einops by coding a custom multi-head self-attention unit and a transformer block
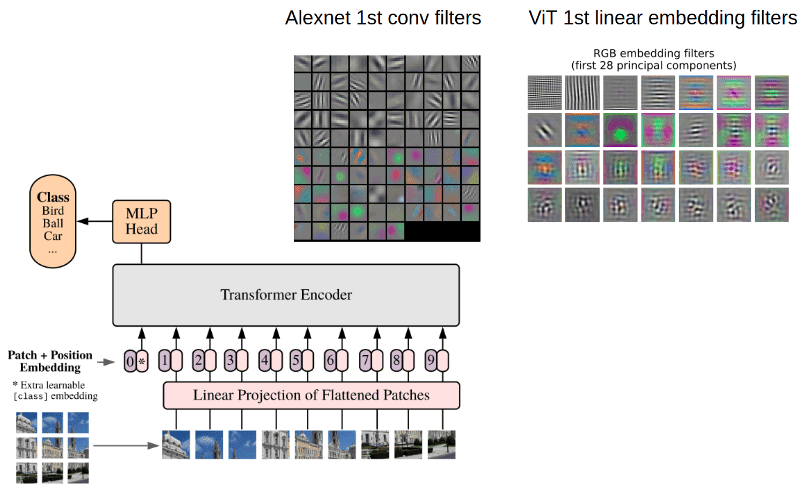
How the Vision Transformer (ViT) works in 10 minutes: an image is worth 16x16 words
In this article you will learn how the vision transformer works for image classification problems. We distill all the important details you need to grasp along with reasons it can work very well given enough data for pretraining.

How Transformers work in deep learning and NLP: an intuitive introduction
An intuitive understanding on Transformers and how they are used in Machine Translation. After analyzing all subcomponents one by one such as self-attention and positional encodings , we explain the principles behind the Encoder and Decoder and why Transformers work so well
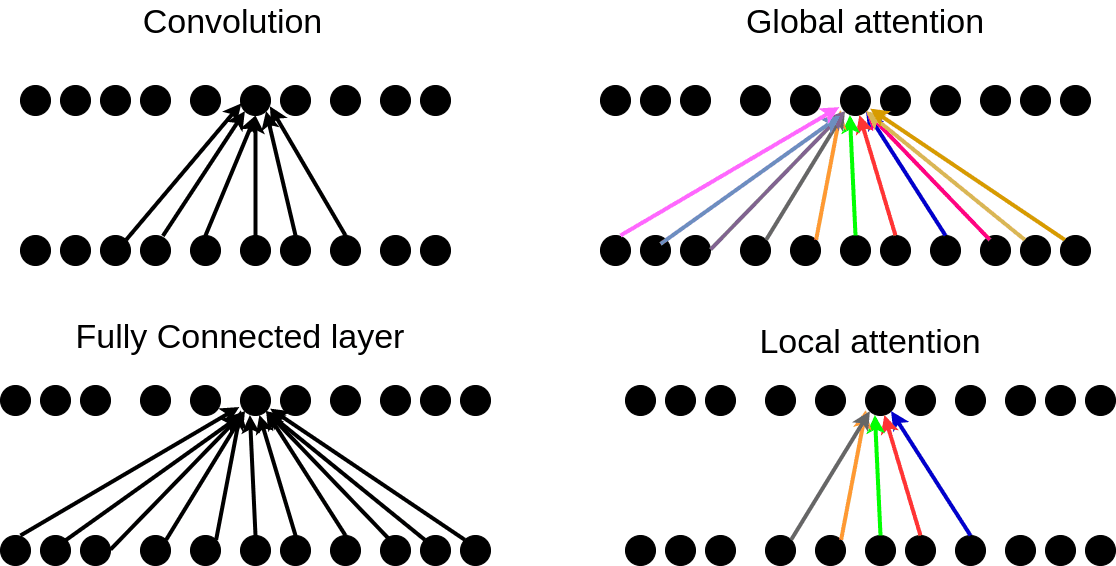
How Attention works in Deep Learning: understanding the attention mechanism in sequence models
New to Natural Language Processing? This is the ultimate beginner’s guide to the attention mechanism and sequence learning to get you started