It is well-established that Vision Transformers (ViTs) can outperform convolutional neural networks (CNNs), such as ResNets in image recognition. But what are the factors that cause ViTs' superior performance? To answer this, we investigate the learned representations of pretrained models.
In this article, we will explore various topics based on high-impact computer vision papers:
The texture-shape cue conflict and the issues that come with supervised training on ImageNet.
Several ways to learn robust and meaningful visual representations, like self-supervision and natural language supervision.
The robustness of ViTs vs CNNs, as well as highlight the intriguing properties that emerge from trained ViTs.
Adversarial Attacks are well-known experiments that help us gain insight into the workings of a classification network. They are designed to fool neural networks by leveraging their gradients (Goodfellow et al. 1). Instead of minimizing the loss by altering the weights, an adversarial perturbation changes the inputs to maximize the loss based on the computed gradients. Let’s look at the adversarial perturbations computed for a ViT and a ResNet model.
 Fig. 1: ViTs and ResNets process their inputs very differently. Source
Fig. 1: ViTs and ResNets process their inputs very differently. Source
As depicted in the above figure, the adversarial perturbations are qualitatively very different. Even though both models may perform similarly in image recognition, why do they have different adversarial perturbations?
Let’s introduce some background knowledge first.
Robustness: We apply a perturbation to the input images (i.e. masking, blurring) and track the performance drop of the trained model. The smaller the performance degradation, the more robust the classifier!
Robustness is measured in supervised setups, so the performance metric is usually classification accuracy. Furthermore, robustness can be defined with respect to model perturbations; for example by removing a few layers. But this is not so common. Note that our definition of robustness always includes a perturbation.
The transformer can attend to all the tokens (16x16 image patches) at each block by design. The originally proposed ViT model from Dosovitskiy et al. 2 already demonstrated that heads from early layers tend to attend to far-away pixels, while heads from later layers do not.
 Fig. 2: How heads of different layers attend to their surround pixels. Source: Dosovitskiy et al. 2
Fig. 2: How heads of different layers attend to their surround pixels. Source: Dosovitskiy et al. 2
Long-range correlations are indeed beneficial for image classification, but is this the only reason for the superior performance of ViTs? For that, we need to take a step back and take a closer look at the representations of CNNs, specifically ResNets as they have been studied in greater depth.
ImageNet-pretrained CNNs are biased towards texture
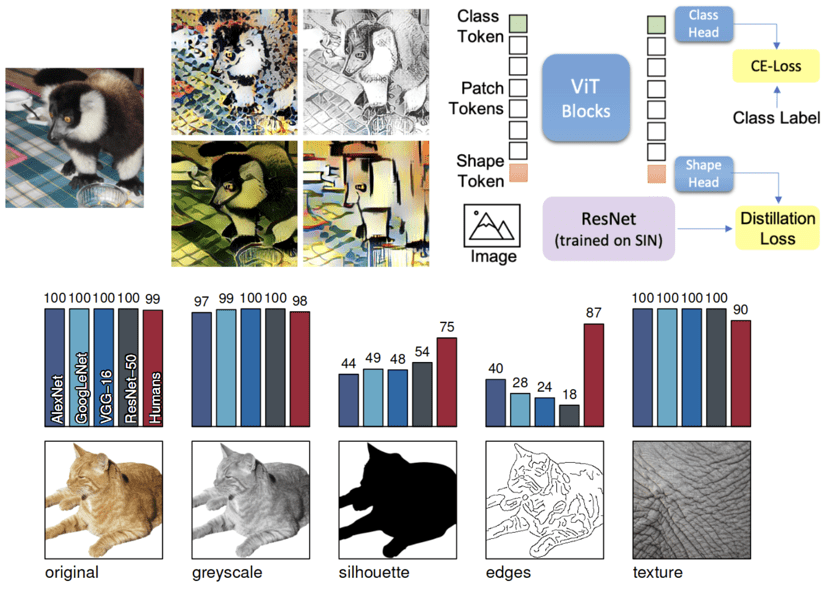
In their paper “Are we done with ImageNet?”, Beyer et al. 3 argue whether existing model simply overfit to the idiosyncrasies of ImageNet’s labeling procedure. To delve deeper into the learned representations of pretrained models, we will focus on the infamous ResNet50 study by 4. More specifically, Geirhos et al. 4 demonstrated that CNNs trained on ImageNet are strongly biased towards recognizing textures rather than shapes. Below is an excellent example of such a case:
 Fig. 3: Classification of a standard ResNet-50 of (a) a texture image (elephant skin: only texture cues); (b) a normal image of a cat (with both shape and texture cues), and (c) an image with a texture-shape cue conflict, generated by style transfer between the first two images. Source: Geirhos et al. 4.
Fig. 3: Classification of a standard ResNet-50 of (a) a texture image (elephant skin: only texture cues); (b) a normal image of a cat (with both shape and texture cues), and (c) an image with a texture-shape cue conflict, generated by style transfer between the first two images. Source: Geirhos et al. 4.
Left: a texture image (elephant skin) that is correctly recognized. Center: a correctly classified image of a lovely cat. Right: when the network is presented with an overlay of the elephant texture with the cat shape (right) the prediction highly favors the texture rather than the object’s shape. This is the so-called texture-shape cue conflict. The image on the right was generated using adaptive instance normalization.
At this point, you may be wondering, what’s wrong with texture?
Neuroscience studies (Landau et al. 5) showed that object shape is the single most important cue for human object recognition. By studying the visual pathway of humans regarding image recognition, researchers identified that the perception of object shape is invariant to most perturbations. So as far as we know, the shape is the most reliable cue.
Intuitively, the object shape remains relatively stable while other cues can be easily distorted by all sorts of noise, such as rain and snow in a real-life scenario 4. Shape-based representations are thus highly beneficial for image classification.
That explains why humans can recognize sketches, paintings, or drawings while neural networks struggle (performance deteriorates significantly).
 Fig. 4: Accuracies and example stimuli for five different experiments without cue conflict. Source: Geirhos et al. 4.
Fig. 4: Accuracies and example stimuli for five different experiments without cue conflict. Source: Geirhos et al. 4.
In the above image, silhouettes and edges are created from traditional computer vision algorithms. It is important to note at this point that all the CNNs were trained on Imagenet using the image label as supervision, which begs the question: is ImageNet part of the problem?
What’s wrong with ImageNet?
Brendel et al. 6 provided sufficient experimental results to state that ImageNet can be “solved” (decently high accuracy) using only local information. In other words, it suffices to integrate evidence from many local texture features rather than going through the process of integrating and classifying global shapes.
The problem? ImageNet learned features generalize poorly in the presence of strong perturbations. This severely limits the use of pretrained models in settings where shape features translate well, but texture features do not.
One example of poor generalization is the Stylized ImageNet (SIN) dataset.
 Fig. 5: The SIN dataset. Left: reference image. Right: Example texture-free images that can be recognized only by shape. Geirhos et al. 4.
Fig. 5: The SIN dataset. Left: reference image. Right: Example texture-free images that can be recognized only by shape. Geirhos et al. 4.
SIN is a synthetic texture-free dataset, wherein the object class can only be determined by learning shape-based representations.
Based on extensive experiments, Geirhos et al. 4 found that texture bias in current CNNs is not by design, but induced by ImageNet training data, which hinders the transferability of those features in more challenging datasets (i.e. SIN).
Hence, supervised ImageNet-trained CNNs are probably taking a “shortcut” by focusing on local textures 4: “If textures are sufficient, why should a CNN learn much else?”
So how can we enforce the model to be texture debiased? Let’s start with a very simple workaround.
Hand-crafted tasks: rotation prediction
Various hand-crafted pretext tasks have been proposed to improve the learned representations. Such pretext tasks can be used either for self-supervised pretraining or as auxiliary objectives. Self-supervised pretraining requires more resources and usually a larger dataset, while the auxiliary objective introduces a new hyperparameter to balance the contribution of the multiple losses.
For instance, Gidaris et al. 7 used rotation prediction for self-supervised pretraining. The core intuition of rotation prediction (typically [0,90,180,270]) is that if someone is not aware of the objects depicted in the images, he cannot recognize the rotation that was applied to them.
 Fig. 6: Applied rotations. Source: Gidaris et al. ICLR 2018
Fig. 6: Applied rotations. Source: Gidaris et al. ICLR 2018
In the next example, the texture is not sufficient for determining whether the zebra is rotated. Thus, predicting rotation requires modeling shape, to some extent.
 Fig. 7: The object's shape can be invariant to rotations, e.g zebra, orange. Source: Hendrycks et al. 8 (NeurIPS 2019)
Fig. 7: The object's shape can be invariant to rotations, e.g zebra, orange. Source: Hendrycks et al. 8 (NeurIPS 2019)
Hendrycks et al. 8 used the rotation prediction as an auxiliary objective on par with the supervised objective. Interestingly, they found that rotation prediction can benefit robustness against adversarial examples, as well as label and input corruption. It also benefits supervised out-of-distribution detection. However, this principle may not be true for other objects such as oranges.
To date, no hand-crafted pretext task (i.e. inpainting, jigsaw puzzles, etc.) has been widely applied, which brings us to the next question: what is our best shot to learn informative representations?
The answer lies in self-supervised joint-embedding architectures.
DINO: self-distillation combined with Vision Transformers
Over the years, a plethora of joint-embedding architectures has been developed. In this blog post, we will focus on the recent work of Caron et al. 9, namely DINO.
 Fig. 8: The DINO architecture. Source: Caron et al. 9.
Fig. 8: The DINO architecture. Source: Caron et al. 9.
Here are the most critical components from the literature of self-supervised learning:
Strong stochastic transformations (cropping, jittering, solarization, blur) are applied to each image x to create a pair x1, x2 (the so-called views).
Self-distillation: The teacher is built from past iterations of the student, where the teacher's weights are an exponential moving average of the student's weights.
Multiple views are created for each image, precisely 8 local (96x96) and 2 global crops (224x224)
The aforementioned components have been previously explored by other joint embedding approaches. Then why DINO is so important?
Well, because this was the first work to show the intriguing property of ViTs to learn class-specific features. Previous works have primarily focused on ResNets.
 Fig. 9: Source: Caron et al. 9.
Fig. 9: Source: Caron et al. 9.
For this visualization, the authors looked at the self-attention of the CLS token on the heads of the last layer. Crucially, no labels are used during the self-supervised training. These maps demonstrate that the learned class-specific features lead to remarkable unsupervised segmentation masks, and visibly correlate with the shape of semantic objects in the images.
Regarding adversarial robustness, Bai et al. 10 claim that ViTs attain similar robustness compared to CNNs in defending against both perturbation-based adversarial attacks and patch-based adversarial attacks.
Therefore, neural networks are still quite sensitive to pixel information. The reason remains the same: the trained models solely rely on the visual signal.
One plausible way to learn more “abstract” representations lies in incorporating existing image-text paired data on the internet without explicitly relying on human annotators. This is the so-called natural language supervision approach, introduced by OpenAI.
Pixel-insensitive representations: natural language supervision
In CLIP 11, Radford et al. scraped a 400M image-text description dataset from the web. Instead of having a single label (e.g. car) and encoding it as a one-hot vector we now have a sentence. The captions are likely more descriptive than mere class labels.
The sentence will be processed by a text transformer and an aggregated representation will be used. In this way, they propose CLIP to jointly train the image and text transformer.
 Fig. 10: Source: Radford et al.
Fig. 10: Source: Radford et al.
Given that the label names are available for the downstream dataset one can do zero-shot classification, by leveraging the text transformer and taking the image-text pair with the maximum similarity.
Notice how robust the model is compared to a supervised ResNet with respect to (w.r.t.) data perturbations like sketches.
 Fig. 11: Source: Radford et al.
Fig. 11: Source: Radford et al.
Since the model was trained with much more data, sketches were likely included in the web-scraped data as well as image captions that are more descriptive than simple class labels. Its accuracy on natural adversarial examples is still remarkable.
Insight: “The presence of features that represent conceptual categories is another consequence of CLIP training” ~ Ghiasi et al. 12.
In contrast to supervised ViTs wherein features detect single objects, CLIP-trained ViTs produce features in deeper layers activated by objects in clearly discernible conceptual categories 12.
 Fig. 12: Features from ViT trained with CLIP that relates to the category of morbidity and music. Source: Ghiasi et al.
Fig. 12: Features from ViT trained with CLIP that relates to the category of morbidity and music. Source: Ghiasi et al.
Left (a): feature activated by what resembles skulls alongside tombstones. The remaining seven images (with the highest activation) include other semantic classes such as bloody weapons, zombies, and skeletons. These classes have very dissimilar attributes pixel-wise, suggesting that the learned feature is broadly related to the abstract concept of “morbidity”. Right (b): we observe that the disco ball features are related to boomboxes, speakers, a record player, audio recording equipment, and a performer.
CLIP models thus create a higher-level organization for the objects they recognize than standard supervised models.
From the above comparison, it is not clear if the superior accuracy stems from the architecture, the pretrained objective, or the enlarged training dataset. Fang et al. 13 have shown through extensive testing that the large robustness gains are a result of the large pretraining dataset. Precisely:
“CLIP’s robustness is dominated by the choice of training distribution, with other factors playing a small or non-existent role. While language supervision is still helpful for easily assembling training sets, it is not the primary driver for robustness” ~ Fang et al. 13.
Now we move back to the common supervised setups.
Robustness of ViTs versus ResNets under multiple perturbations
Google AI has conducted extensive experiments to study the behavior of supervised trained models under different perturbation setups. In the standard supervised arena, Bhojanapalli et al. 14 explored how ViTs and ResNets behave in terms of their robustness against perturbations to inputs as well as to model-based perturbations.
 Fig. 13: Source: Bhojanapalli et al. 14
Fig. 13: Source: Bhojanapalli et al. 14
ILSVRC-2012 stands for ImageNet, ImageNet-C is a corrupted version of ImageNet, and ImageNet-R includes images with real-world distribution shifts. ImageNet-A consists of natural adversarial examples 15 as illustrated below:
 Fig. 14: Natural Adversarial Examples from Dan Hendrycks et al. Source
Fig. 14: Natural Adversarial Examples from Dan Hendrycks et al. Source
Here, the black text is the actual class, and the red text is a ResNet-50 prediction and its confidence.
The core findings of this study 14 are summarized below:
ViTs scale better with model and dataset size than ResNets. More importantly, the accuracy of the standard ImageNet validation set is predictive of performance under several data perturbations.
ViT robustness w.r.t. model-based perturbations: The authors noticed that besides the first transformer block, one can remove any single block, without substantial performance deterioration. Moreover, removing self-attention layers hurts more than removing MLP layers.
ViT robustness w.r.t. patch size: In addition, ViTs have different robustness with respect to their patch size. Precisely, the authors found that smaller patch sizes make ViT models more robust to spatial transformations (i.e. roto-translations), but also increase their texture bias (undesirable). Intuitively, a patch size of 1 would discard all the spatial structure (flattened image) while a patch size close to the image size would limit fine-grained representations. For example, multiple objects in the same patch would have the same embedding vector. The rough natural language equivalent to a patch size of 1 would be character-level encoding. The big patch size would conceptually correspond to representing multiple sentences with a single embedding vector.
ViT robustness w.r.t. global self-attention: Finally, restricting self-attention to be local, instead of global, has a relatively small impact on the overall accuracy.
Experimental results from this study are quite convincing, but they do not provide any explanation whatsoever. This brings us to the NeurIPS 2021 paper called “Intriguing properties of ViTs.”
Intriguing Properties of Vision Transformers
In this excellent work, Naseer et al. 16 investigated the learned representations of ViTs in greater depth. Below are the main takeaways:
1) ViTs are highly robust to occlusions, permutations, and distribution shifts.
 Fig. 15: Robustness against occlusions study. Source: Naseer et al. NeurIPS 2021
Fig. 15: Robustness against occlusions study. Source: Naseer et al. NeurIPS 2021
2) The robustness w.r.t. occlusions is not due to texture bias. ViTs are significantly less biased towards local textures, compared to CNNs.
 Fig. 16: Source: Naseer et al. NeurIPS 2021
Fig. 16: Source: Naseer et al. NeurIPS 2021
The latter finding is consistent with a recent work that applied a low-pass filter in the images 12. Textures are known to be high-frequency features. Thus a smaller low-pass threshold retains less texture.
 Fig. 17: Source: Ghiasi et al.
Fig. 17: Source: Ghiasi et al.
ResNets are more dependent on high-frequency (and probably texture-related information) than ViTs.
3) Using ViTs to encode shape-based representation leads to an interesting consequence of accurate semantic segmentation without pixel-level supervision.
 Fig. 18: Source: Naseer et al. NeurIPS 2021
Fig. 18: Source: Naseer et al. NeurIPS 2021
Automatic segmentation of images using the CLS token. Top: Supervised DeiT-S model. Bottom: SIN (Stylized ImageNet) trained DeiT-S.
To enforce shape-based representation they used token-based knowledge distillation. Therein, the model auxiliary aims to match the output of a pretrained ResNet on SIN. The KL divergence is used as a distillation loss.
 Fig. 19: Token-based distillation with ViTs. Source: Naseer et al. NeurIPS 2021
Fig. 19: Token-based distillation with ViTs. Source: Naseer et al. NeurIPS 2021
The emerged background segmentation masks are quite similar to DINO. This fact indicates that both DINO and the shape-distilled ViT (DeiT) learn shape-based representations.
4) The learned ViT features from multiple attention layers (CLS tokens) can be combined to create a feature ensemble, leading to high accuracy rates across a range of classification datasets.
 Fig. 20: Top-1 (%) for ImageNet val. set for class tokens produced by each ViT block. Source: Naseer et al. NeurIPS 2021
Fig. 20: Top-1 (%) for ImageNet val. set for class tokens produced by each ViT block. Source: Naseer et al. NeurIPS 2021
The top-1 (%) classification accuracy on the validation set of ImageNet is reported, using the CLS tokens produced by each ViT block.
“Class tokens from the last few layers exhibit the highest performance indicating the most discriminative tokens.” ~ Naseer et al.
5) ViT features generalize better than the considered CNNs. Crucially, the robustness and superiority of ViT features can be attributed to the flexible and dynamic receptive fields that probably originate from the self-attention mechanism.
 Fig. 21: ViT features are more transferable. Source: Naseer et al. NeurIPS 2021
Fig. 21: ViT features are more transferable. Source: Naseer et al. NeurIPS 2021
Finally, we present a concurrent work to 16, that studied ViT robustness.
Vision Transformers are Robust Learners
Sayak Paul and Pin-Yu Chen 17 investigated the robustness of ViTs against: a) corruptions, b) perturbations, c) distribution shifts, and d) natural adversarial examples. More importantly, they used a stronger CNN-based baseline called BiT 18. The core results are the following:
A longer pretraining schedule and larger pretraining dataset improve robustness (in line with 14).
Attention is key to robustness, which is consistent with all the presented works.
ViTs have better robustness to occlusions (image masking etc.) as shown in 16.
ViTs have a smoother loss landscape to input perturbations (see below).
 Fig. 22: Loss progression (mean and standard deviation) ViT-L/16 and BiT under different PGD adversarial attacks
Fig. 22: Loss progression (mean and standard deviation) ViT-L/16 and BiT under different PGD adversarial attacks
Core Takeaways
To conclude, here is a brief list of the most critical takeaways from this blog post:
ViTs scale better with model and dataset size than CNNs.
ImageNet-pretrained CNNs are biased towards texture.
Shape-based representations are more robust to out-of-distribution generalization (more transferable) compared to texture-based ones.
ViTs are significantly less biased towards local textures than CNNs.
ViTs are equally bad to adversarial attacks and natural adversarial examples as CNNs.
ViTs are highly robust to occlusions, permutations, and distribution shifts.
ViTs trained with shape-based distillation or self-supervised learning (DINO) lead to representations that implicitly encode the foreground (background segmentation maps).
ViTs achieve superior out-of-distribution generalization than CNNs.
If you find our work interesting, you can cite us as follows:
@article{adaloglou2023robustness,title = "Understanding Vision Transformers (ViTs): Hidden properties, insights, and robustness of their representations",author = "Adaloglou, Nikolas, Kaiser, Tim",journal = "https://theaisummer.com/",year = "2023",url = "https://theaisummer.com/vit-properties/"}
Alternatively, support us by sharing this article on social media. It feels extremely rewarding and we really appreciate it! As always, thank you for your interest in deep learning and AI.
References
- Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572.↩
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.↩
- Beyer, L., Hénaff, O. J., Kolesnikov, A., Zhai, X., & Oord, A. V. D. (2020). Are we done with imagenet?. arXiv preprint arXiv:2006.07159.↩
- Geirhos, R., Rubisch, P., Michaelis, C., Bethge, M., Wichmann, F. A., & Brendel, W. (2018). ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv preprint arXiv:1811.12231.↩
- Landau, B., Smith, L. B., & Jones, S. S. (1988). The importance of shape in early lexical learning. Cognitive development, 3(3), 299-321.↩
- Brendel, W., & Bethge, M. (2019). Approximating cnns with bag-of-local-features models works surprisingly well on imagenet. arXiv preprint arXiv:1904.00760.↩
- Gidaris, S., Singh, P., & Komodakis, N. (2018). Unsupervised representation learning by predicting image rotations. arXiv preprint arXiv:1803.07728.↩
- Hendrycks, D., Mazeika, M., Kadavath, S., & Song, D. (2019). Using self-supervised learning can improve model robustness and uncertainty. Advances in neural information processing systems, 32.↩
- Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., & Joulin, A. (2021). Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 9650-9660).↩
- Bai, Y., Mei, J., Yuille, A. L., & Xie, C. (2021). Are transformers more robust than cnns?. Advances in Neural Information Processing Systems, 34, 26831-26843.↩
- Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PMLR.↩
- Ghiasi, A., Kazemi, H., Borgnia, E., Reich, S., Shu, M., Goldblum, M., ... & Goldstein, T. (2022). What do Vision Transformers Learn? A Visual Exploration. arXiv preprint arXiv:2212.06727.↩
- Fang, A., Ilharco, G., Wortsman, M., Wan, Y., Shankar, V., Dave, A., & Schmidt, L. (2022, June). Data determines distributional robustness in contrastive language image pre-training (clip). In International Conference on Machine Learning (pp. 6216-6234). PMLR.↩
- Bhojanapalli, S., Chakrabarti, A., Glasner, D., Li, D., Unterthiner, T., & Veit, A. (2021). Understanding robustness of transformers for image classification. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 10231-10241).↩
- Hendrycks, D., Zhao, K., Basart, S., Steinhardt, J., & Song, D. (2021). Natural adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 15262-15271).↩
- Naseer, M. M., Ranasinghe, K., Khan, S. H., Hayat, M., Shahbaz Khan, F., & Yang, M. H. (2021). Intriguing properties of vision transformers. Advances in Neural Information Processing Systems, 34, 23296-23308.↩
- Paul, S., & Chen, P. Y. (2022, June). Vision transformers are robust learners. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 36, No. 2, pp. 2071-2081).↩
- Kolesnikov, A., Beyer, L., Zhai, X., Puigcerver, J., Yung, J., Gelly, S., & Houlsby, N. (2020). Big transfer (bit): General visual representation learning. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16 (pp. 491-507). Springer International Publishing.↩

* Disclosure: Please note that some of the links above might be affiliate links, and at no additional cost to you, we will earn a commission if you decide to make a purchase after clicking through.