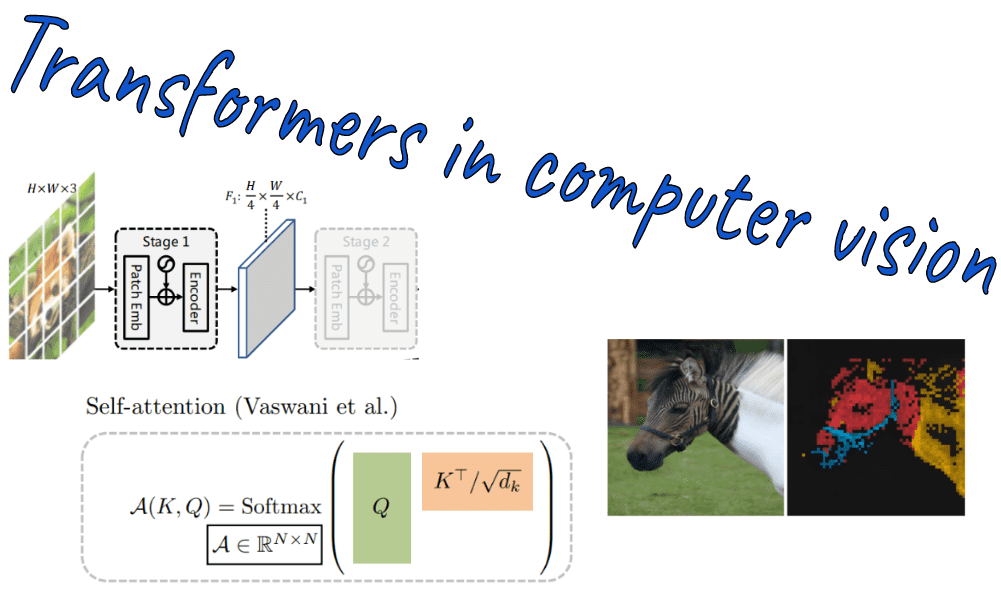
You are probably already aware of the Vision Transformer (ViT). What came after its initial submission is the story of this blog-post. We will explore multiple orthogonal research directions on ViTs. Why? Because chances are that you are interested in a particular task like video summarization. We will address questions like how can you adapt/use ViT on your computer vision problem, what are the best ViT-based architectures, training tricks and recipes, scaling laws, supervised vs self-supervised pre-training, etc.
Even though many of the ideas come from the NLP world like linear and local attention, the ViT arena has made a name by itself. Ultimately, it’s the same operation in both fields: self-attention. It’s just applied in patch embeddings instead of word embeddings.
 Source: Transformers in Vision
Source: Transformers in Vision
Therefore, here I will cover the directions that I find interesting to pursue.
Important note: ViT and its prerequisites are not covered here. Thus, to optimize your understanding I would highly suggest taking a decent look at previous posts on self-attention, the original ViT, and certainly Transformers. If you like our transformer series, consider buying us a coffee!
DeiT: training ViT on a reasonable scale
Knowledge distillation
In deep learning competitions like Kaggle, ensembles are super famous. Basically, an ensemble (aka teacher) is when we average multiple trained model outputs for prediction. This simple technique is great for improving test-time performance. However, it becomes times slower during inference, where indicates the number of trained models. This is an issue when we deploy such neural networks in embedded devices. To address it, an established technique is knowledge distillation.
Knowledge distillation simply trains a new randomly initialized model to match the output of the ensemble (an N times bigger set of models). The output of a well-trained ensemble model is some mixed version of a set of real labels, i.e. 88% cat, 7% tiger, 5% dog.
It turns out this sneaky trick works very well. No underlying theory to support this experimental claim though. Why does matching the output distribution of an ensemble give us on-par test performance with the ensemble is yet to be discovered. Even more mysterious is the fact that by using the ensemble’s output (kinda biased smooth labels) we observe gains VS the true labels. For more info, I am highly suggesting Microsoft’s seminal work on the topic.
“Training data-efficient image transformers & distillation through attention” 1, aka DeiT, was the first work to show that ViTs can be trained solely on ImageNet without external data.
To do that, they used the already trained CNN models from the Resnet nation as a single teacher model. Intuitively, given the strong data assumptions of CNNs (inductive biases), CNNs make better teacher networks than ViTs.
Self-distillation
Astonishingly, we see that this is also possible by performing knowledge distillation against an individual model of the same architecture, called teacher. This process is called self-distillation and it’s coming from the paper “Be Your Own Teacher”.
Self-distillation is a knowledge distillation with . Counterintuitively, self-distillation (using a single trained model with identical architecture), the test accuracy can also be improved. There are no theories behind this phenomenon yet. Neural networks just love smooth stuff!
Hard-label Distillation of ViTs: DeiT training strategy
In this approach, an additional learnable global token, called the distillation token, is concatenated to the patch embeddings of ViT. Critically, the distillation token comes from a trained teacher CNN backbone. By fusing the CNN features into the self-attention layers of the transformers, they trained it on Imagenet’s 1M data.
 An overview of DeiT 1
An overview of DeiT 1
DeiT is trained with the loss function:
where CE is the cross-entropy loss function, is the softmax function, and are the student’s output (bottom leftmost and rightmost out tokens) derived respectively from the class and distillation tokens, and and are respectively the ground truth and the teacher’s output.
This distillation technique allows the model to have fewer data and super strong data augmentation, which may cause the ground truth label to be imprecise. In such a case, it looks like the teacher network will produce a more suitable label.
The resulting model family, namely Data efficient image Transformers (DeiTs), were on par with EfficientNet on the accuracy/step time, but still behind on accuracy/parameters efficiency.
Apart from distillation, they played a lot with image augmentation to compensate for the no additional data available. You can learn more about it in this summary video of Deit:
Finally, DeiT relies on data regularization techniques like stochastic depth. Ultimately, strong augmentations and regularization are limiting ViT’s tendency to overfit in the small data regimes.
Pyramid Vision Transformer
 Overall architecture of the proposed Pyramid Vision Transformer (PVT). Source
Overall architecture of the proposed Pyramid Vision Transformer (PVT). Source
To overcome the quadratic complexity of the attention mechanism, Pyramid Vision Transformers2 (PVTs) employed a variant of self-attention called Spatial-Reduction Attention (SRA), characterized by a spatial reduction of both keys and values. This is like the Linformer attention3 idea from the NLP arena.
By applying SRA, the spatial dimensions of the features slowly decrease throughout the model. Moreover, they enhance the notion of order by applying positional embeddings in all their transformer blocks. To this end, PVT has been applied as a backbone to object detection, and semantic segmentation, where one has to deal with high-resolution images.
Later on, the authors further improved their PVT model. Compared to PVT, the main improvements of PVT-v24 are summarized as follows:
overlapping patch embedding
convolutional feedforward networks
linear-complexity self-attention layers.
 PVT-v2 4
PVT-v2 4
By leveraging overlap regions/patches, PVT-v24 can obtain more local continuity of images representations.
Overlapping patches is an easy and general idea for improving ViT, especially for dense tasks (e.g. semantic segmentation).
The convolution between Fully Connected (FC) layers removes the need for fixed-size position encoding in every layer. A 3x3 depth-wise Conv with zero padding () is introduced to compensate for the removal of position encoding in the model. They still exist but only on the input. This process enables processing multiple image resolutions more flexibly.
Finally, with key and value pooling (with ), the self-attention layer enjoys a CNN-like complexity.
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
This paper aims to establish the idea of locality from standard NLP transformers, namely local or window attention:
 Source: Big Bird: Transformers for Longer Sequences, by Zaheer et al.
Source: Big Bird: Transformers for Longer Sequences, by Zaheer et al.
In the SWIN transformer, the local self-attention is applied in non-overlapping windows. The window-to-window communication in the next layer produces a hierarchical representation by progressively merging the windows themselves5.
 Source: SWIN transformer5
Source: SWIN transformer5
Let’s take a closer look at the image. On the left side, we have a regular window partitioning scheme for the first layer, and self-attention is computed within each window. On the right side, we see the second layer where the window partitioning is shifted by 2 image patches. This results in crossing the boundaries of the previous windows.
Local self-attention scales linearly with image size instead of for sequence length N and M window size. By adding many local layers with merging, we have a global representation. Moreover, the feature map’s spatial dimensions have been significantly decreased. The authors claim promising results on both ImageNet-1K and ImageNet-21K.
Find more about the SWIN transformer5 in AI Coffee Break with Letitia awesome video:
Self-supervised training on Vision Transformers: DINO
Facebook AI research has proposed a powerful framework6 for training Vision Transformer in large scale unsupervised data. The proposed self-supervised system creates such robust representations that you don’t even need to fine-tune a linear layer on top of it. This was observed by applying K-Nearest Neighbours (NN) on the frozen trained features of the dataset. The authors found that a well-trained ViT can reach a 78.3% top-1accuracy on ImageNet without labels!
Let’s see the self-supervised framework:
 DINO training scheme. Source DINO 6
DINO training scheme. Source DINO 6
In contrast to other self-supervised models, they used cross-entropy loss, as one would do in a typical self-distillation scenario. Nonetheless, the teacher model here is randomly initialized and its parameters are updated with an exponential moving average from the student parameters. To make it work a temperature softmax is applied to both teacher and student with different temperatures. Specifically, the teacher gets a smaller temperature, which means sharper prediction. On top of that, they used the multi-crop idea that was found to work super well from SWAV, where the teacher sees only global views while the student has access to both global and local views of the transformed input image.
This framework is not as beneficial for CNN architectures as it is for vision transformers. Wondering what kind of features you can extract from images in this way?
 DINO head attention visualization. Source DINO 6
DINO head attention visualization. Source DINO 6
The authors visualized the self-attention head outputs from a trained VIT. These attention maps illustrate that the model automatically learns class-specific features leading to unsupervised object segmentation e.g. foreground vs background.
This property emerges in self-supervised pretrained convnets also but you need a special methodology to visualize the features. More importantly, self-attention heads learn complementary information that is illustrated by using a different colour for each head. This is not at all what you get by self-attention by default.
 DINO multiple attention heads visualization. Source DINO 6
DINO multiple attention heads visualization. Source DINO 6
Scaling Vision Transformers
Deep learning is all about scale. Indeed, scale is a key component in pushing the state-of-the-art. In this study7 by Zhai et al. from Google Brain Research, the authors train a slightly modified ViT model with 2 billion parameters, which attains 90.45% top-1 accuracy on ImageNet7. The generalization of this over-parametrized beast is tested on few-shot learning: it reaches 84.86% top-1 accuracy on ImageNet with only 10 examples per class.
Few-shot learning refers to fine-tuning a model with an extremely limited number of samples. The goal of few-shot learning incentivizes generalization by slightly adapting the acquired pretraining knowledge to the particular task. If huge models were pre-trained successfully, then it makes sense to perform well with a very limited understanding (provided by just a few examples) of the downstream task.
Below are some core contributions and the main results of this paper:
Representation quality can be bottlenecked by model size, given that you have enough data to feed it :)
Large models benefit from additional supervised data, even beyond 1B images.
 Switching from a 300M image dataset (JFT-300M) to 3 billion images (JFT-3B) without any further scaling. Source
Switching from a 300M image dataset (JFT-300M) to 3 billion images (JFT-3B) without any further scaling. Source
The effect of switching from a 300M image dataset (JFT-300M) to 3 billion images (JFT-3B) without any further scaling is depicted in the figure. Both medium (B/32) and large (L/16) models benefit from adding data, roughly by a constant factor. The results are obtained on few-shot (linear) evaluation throughout training.
Big models are more sample efficient, reaching the same level of error rate with fewer seen images.
To save memory, they removed the class token (cls). Instead, they evaluated global average pooling and multi-head attention pooling to aggregate representation from all patch tokens.
They used a different weight decay for the head and the rest of the layers called “body”. The authors nicely demonstrate this in the following image. The box value is the few-shot accuracy, while the horizontal and vertical axis signifies the body and head weight decay, respectively. Surprisingly, a stronger decay on the head yields the best results. The authors speculate that a strong weight decay in the head results in representations with a larger margin between classes.
 Weight decay decoupling effect. Source: Scaling Vision Transformers 7
Weight decay decoupling effect. Source: Scaling Vision Transformers 7
This one is, I believe, the most interesting finding that can be applied more broadly in pretraining ViTs.
They used a warm-up phase at the beginning of training, as well as a cooldown phase at the end, where the learning rate is linearly annealed toward zero. Moreover, they used the Adafactor optimizer, which results in a 50% memory overhead compared to the conventional Adam.
In the same wavelength, you can find another large-scale study: “How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers”
Replacing self-attention: independent token + channel mixing methods
Self-attention is known to act as an information routing mechanism with its fast weights. To that end, there are 3 papers so far telling the same story: replace self-attention with 2 information mixing layers; one for mixing tokens (projected patch vectors) and one for mixing channel/feature information.
MLP-Mixer
The infamous MLP-Mixer8 contains two MLP layers: the first one is applied independently to image patches (i.e. “mixing” the per-location features), and the other across patches (i.e. “mixing” spatial information).
 MLP-Mixer architecture8
MLP-Mixer architecture8
XCiT: Cross-Covariance Image Transformers
Another recent architecture, called XCiT9, aims to modify the core building block of ViT: self-attention, which is applied over the token dimension.
 XCiT architecture9
XCiT architecture9
XCA: For info mixing, the authors proposed a cross-covariance attention (XCA) function that operates along the feature dimension of the tokens, rather than along the tokens themselves. Importantly, this method only works with L2-normalized sets of queries, keys and values. The L2-norm is indicated with the hat above the K and Q letters. The result of the multiplication is also normalized to [-1,1] before softmax.
Local Patch Interaction: To enable explicit communication across patches they add two depth-wise 3×3 convolutional layers with Batch Normalization and GELU non-linearity in between. Remember, depthwise convolution is applied to each channel - here patches - independently.
 Image Credit: Chi-Feng Wang - A Basic Introduction to Separable Convolutions. Source
Image Credit: Chi-Feng Wang - A Basic Introduction to Separable Convolutions. Source
I personally prefer the term channel-wise convolution, but that’s another story.
For more info, Yannic Kilcher summarizes the main contribution of this work along with some hot remarks:
ConvMixer
Self-attention and MLPs are theoretically more general modelling mechanisms since they allow large receptive fields and content-aware behaviour. Nonetheless, the inductive bias of convolution has undeniable results in computer vision tasks.
Motivated by this, another convnet-based variant has been proposed, called ConvMixer. The main idea is that it operates directly on patches as input, separates the mixing of spatial and channel dimensions, and maintains equal size and resolution throughout the network.
 ConvMixer architecture 10
ConvMixer architecture 10
More specifically, depthwise convolutions are responsible for mixing spatial locations while pointwise convolution (1x1xchannels kernels) for mixing channel locations as illustrated below:
 Source: Depthwise Convolution is All You Need for Learning Multiple Visual Domains
Source: Depthwise Convolution is All You Need for Learning Multiple Visual Domains
Mixing distant spatial locations is achieved by choosing large kernel sizes to create a large receptive field.
Multiscale Vision Transformers
CNN backbone architectures benefit from the gradual increase of channels while reducing the spatial dimension of the feature maps. Similarly, Multiscale Vision Transformers11 (MViT) leverages the idea of combining multi-scale feature hierarchies with vision transformer models. In practice, starting from the initial image size with 3 channels, the authors gradually expand (hierarchically) the channel capacity while reducing the spatial resolution.
As a result, a multiscale pyramid of features is created. Intuitively, early layers will learn high-spatial with simple low-level visual information, while deeper layers are responsible for complex, high-dimensional features11. Code is also available.
 Illustration of MViT 11
Illustration of MViT 11
Next, we will move to more specific computer vision application domains.
Video classification: Timesformer
After the success in image tasks, vision transformers were applied in video recognition. Here I present two architectures:
 Block-based vs architecture/module-based space-time attention architectures for video recognition. Right: An Image is Worth 16x16 Words, What is a Video Worth? 12 Left: Is Space-Time Attention All You Need for Video Understanding? 13
Block-based vs architecture/module-based space-time attention architectures for video recognition. Right: An Image is Worth 16x16 Words, What is a Video Worth? 12 Left: Is Space-Time Attention All You Need for Video Understanding? 13
Right: Zooming out on an architectural level now. The proposed method applied a spatial transformer to the projected image patches and then had another network responsible for capturing time correlations. This resembles the CNN+LSTM winning strategy for video-based processing.
Left: Space-time attention that can be implemented at the self-attention level. Best combination in the red box. That is by sequentially applying attention in the time domain by treating image frames as tokens first. Then, combined space attention in both spatial dimensions is applied before the MLP projection. My reimplementation is available in the
self-attention-cvlibrary. Below is a t-SNE visualization of the method:
 Feature visualization with t-SNE of Timesformer12.
Feature visualization with t-SNE of Timesformer12.
“Each video is visualized as a point. Videos belonging to the same action category have the same colour. The TimeSformer with divided space-time attention learns semantically more separable features than the TimeSformer with space-only attention or ViT.” ~ from the paper
ViT in semantic segmentation: SegFormer
One very well configured transformer setup was proposed by NVidia, named SegFormer13.
SegFormer has interesting design components. First, it consists of a hierarchical transformer encoder that outputs multiscale features. Secondly, it does not need positional encoding, which deteriorates performance when the testing resolution differs from training. SegFormer13 uses a super simple MLP decoder that aggregates the multiscale features of the encoder.
Contrary to ViT, small image patches are taken e.g. 4 x 4, which is known to favour dense prediction tasks. The proposed transformer encoder outputs multi-level features at of the original image resolution. These multi-level features to the MLP decoder to predict the segmentation mask.
 Segformer architecture13
Segformer architecture13
Mix-FFN: To alleviate from positional encodings, they used 3 × 3 Convs with zero padding to leak location information. Mix-FFN can be formulated as:
Efficient self-attention is the attention proposed in PVT. It uses a reduction ratio to reduce the length of the sequence. The results can be measured qualitatively by visualizing the Effective Receptive Field (ERF):

”SegFormer’s encoder naturally produces local attentions which resemble convolutions at lower stages, while being able to output highly non-local attentions that effectively capture contexts at Stage-4. As shown with the zoom-in patches, the ERF of the MLP head (blue box) differs from Stage-4 (red box) with a significantly stronger local attention besides the non-local attention.” ~ Xie et al.
The official video demonstrates the remarkable results in the CityScapes dataset:
Vision Transformers in Medical imaging: Unet + ViT = UNETR
Even though there were other attempts on medical imaging, this paper provides the most convincing results. In this approach, ViT was adapted for 3D medical image segmentation. The authors showed that a simple adaptation was sufficient to improve over baselines on several 3D segmentation tasks.
In essence, UNETR14 utilizes a transformer as the encoder to learn sequence representations of the input volume. Similar to Unet models, it aims to effectively capture the global multi-scale information that can be passed to the decoder with long skip connections. Skip connections are formed at different resolutions to compute the final semantic segmentation output.
 Unetr architecture 14
Unetr architecture 14
My humble reimplementation of UNETR is available on self-attention-cv. Below are some segmentation results from the paper:

Conclusion & Support
To conclude, I would say that there are many things yet to be discovered and push the boundaries of image recognition to the next level. Summing thighs up, there are multiple directions on improving/building upon ViT:
Looking for new “self-attention” blocks (XCIT)
Looking for new combinations of existing blocks and ideas from NLP (PVT, SWIN)
Adapting ViT architecture to a new domain/task (i.e. SegFormer, UNETR)
Forming architectures based on CNN design choices (MViT)
Studying scaling up and down ViTs for optimal transfer learning performance.
Searching for suitable pretext task for deep unsupervised/self-supervised learning (DINO)
And that’s all for today! Thank you for your interest in AI. Writing takes me a significant amount of time to contribute to the open-source/open-access ML/AI community. If you really learn from our work, you can support us by sharing our work or by making a small donation.
Stay motivated and positive!
N.
Cited as:
@article{adaloglou2021transformer,title = "Transformers in Computer Vision",author = "Adaloglou, Nikolas",journal = "https://theaisummer.com/",year = "2021",howpublished = {https://github.com/The-AI-Summer/transformers-computer-vision},}
References
- Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., & Jégou, H. (2021, July). Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning (pp. 10347-10357). PMLR.↩
- Wang, W., Xie, E., Li, X., Fan, D. P., Song, K., Liang, D., ... & Shao, L. (2021). Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. arXiv preprint arXiv:2102.12122.↩
- Wang, S., Li, B. Z., Khabsa, M., Fang, H., & Ma, H. (2020). Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768. ↩
- Wang, W., Xie, E., Li, X., Fan, D. P., Song, K., Liang, D., ... & Shao, L. (2021). Pvtv2: Improved baselines with pyramid vision transformer. arXiv preprint arXiv:2106.13797.↩
- Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., ... & Guo, B. (2021). Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030.↩
- Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., & Joulin, A. (2021). Emerging properties in self-supervised vision transformers. arXiv preprint arXiv:2104.14294.↩
- Zhai, X., Kolesnikov, A., Houlsby, N., & Beyer, L. (2021). Scaling vision transformers. arXiv preprint arXiv:2106.04560.↩
- Tolstikhin, I., Houlsby, N., Kolesnikov, A., Beyer, L., Zhai, X., Unterthiner, T., ... & Dosovitskiy, A. (2021). Mlp-mixer: An all-mlp architecture for vision. arXiv preprint arXiv:2105.01601.↩
- El-Nouby, A., Touvron, H., Caron, M., Bojanowski, P., Douze, M., Joulin, A., ... & Jegou, H. (2021). XCiT: Cross-Covariance Image Transformers. arXiv preprint arXiv:2106.09681.↩
- Patches Are All You Need? Anonymous ICLR 2021 submission ↩
- Fan, H., Xiong, B., Mangalam, K., Li, Y., Yan, Z., Malik, J., & Feichtenhofer, C. (2021). Multiscale vision transformers. arXiv preprint arXiv:2104.11227.↩
- Bertasius, G., Wang, H., & Torresani, L. (2021). Is Space-Time Attention All You Need for Video Understanding?. arXiv preprint arXiv:2102.05095.↩
- Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J. M., & Luo, P. (2021). SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv preprint arXiv:2105.15203.↩
- Hatamizadeh, A., Yang, D., Roth, H., & Xu, D. (2021). Unetr: Transformers for 3d medical image segmentation. arXiv preprint arXiv:2103.10504.↩

* Disclosure: Please note that some of the links above might be affiliate links, and at no additional cost to you, we will earn a commission if you decide to make a purchase after clicking through.