
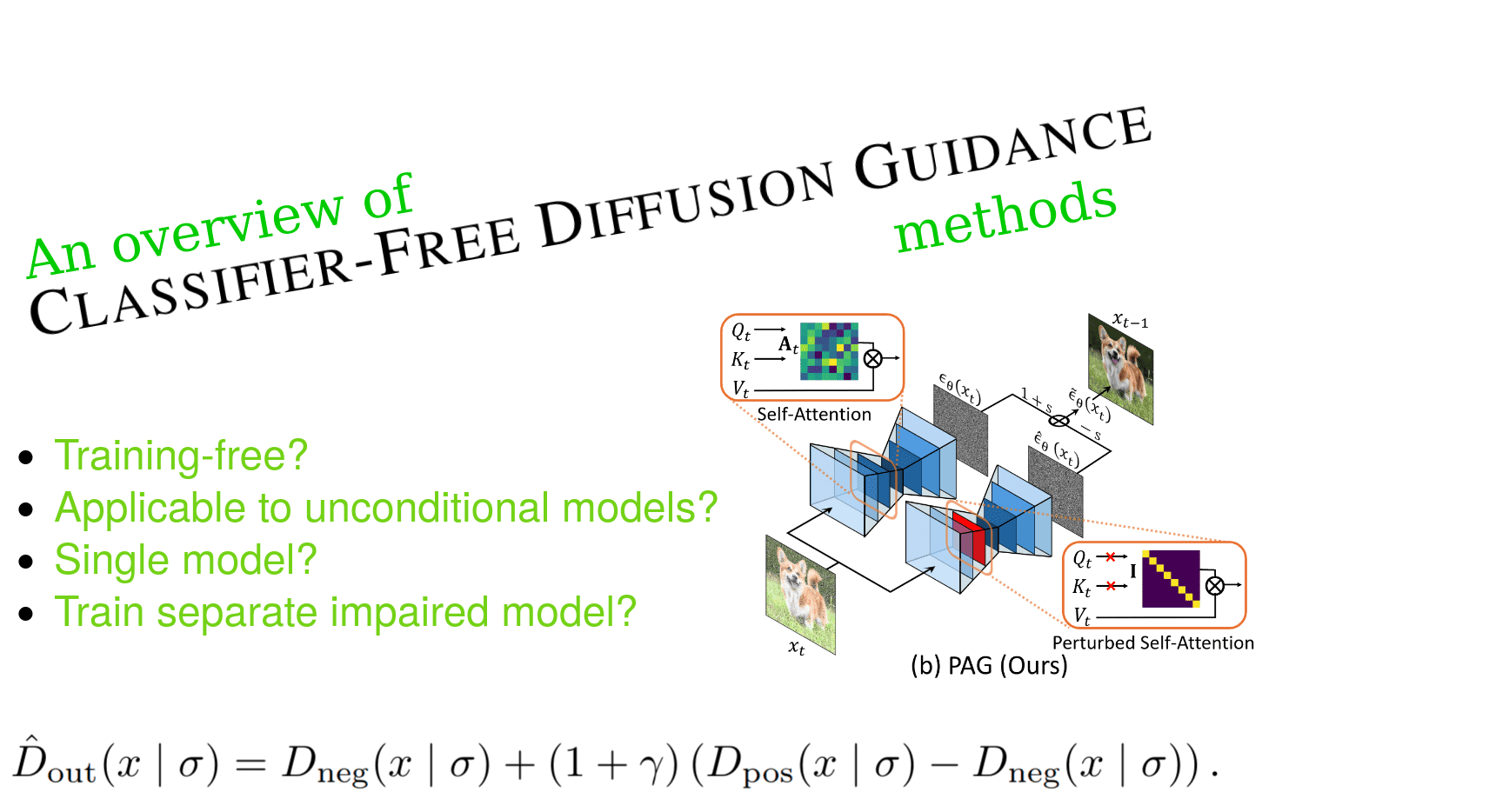
An overview of classifier-free diffusion guidance: impaired model guidance with a bad version of itself (part 2)
How to apply classifier-free guidance (CFG) on your diffusion models without conditioning dropout? What are the newest alternatives to generative sampling with diffusion models? Find out in this article!

An overview of classifier-free guidance for diffusion models
Learn more about the nuances of classifier-free guidance, the core sampling mechanism of current state-of-the-art image generative models called diffusion models.

ICCV 2023 top papers, general trends, and personal picks
Do you want to learn all the latest state-of-the-art methods of the last year? Learn about the best and most famous papers that made the cut from this year’s ICCV. See the latest trends in AI and computer vision.
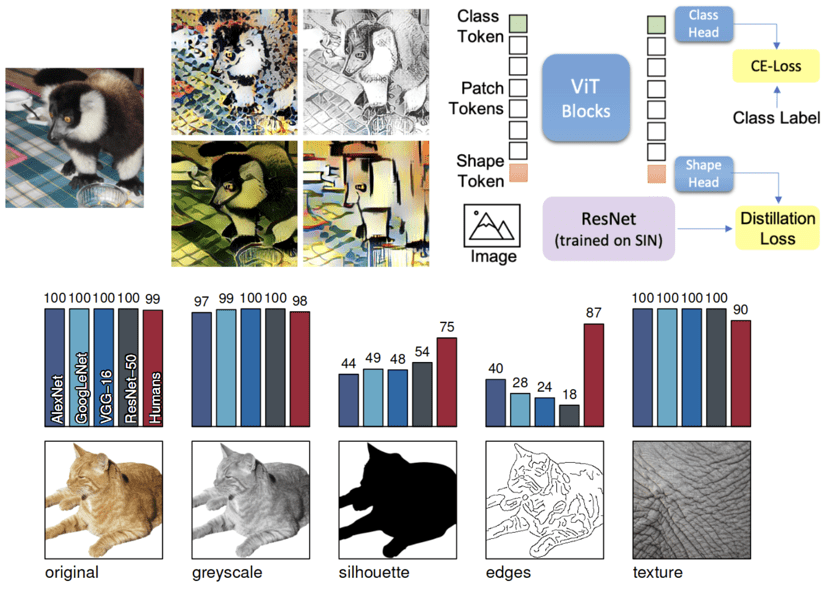
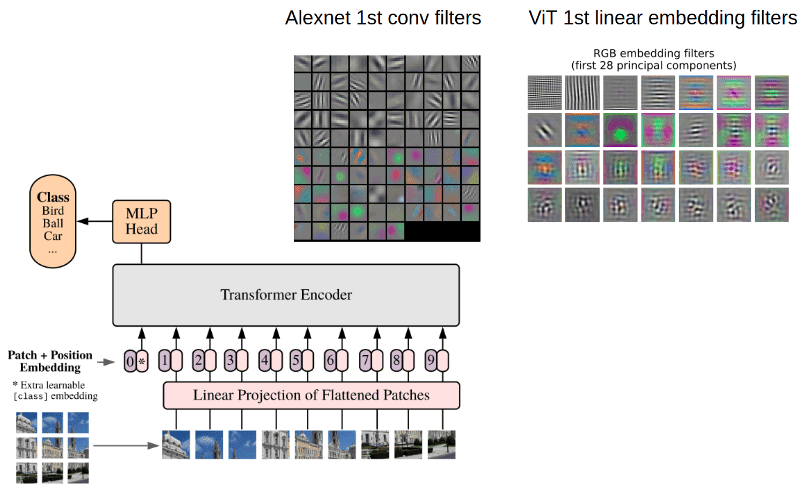
Understanding Vision Transformers (ViTs): Hidden properties, insights, and robustness of their representations
We study the learned visual representations of CNNs and ViTs, such as texture bias, how to learn good representations, the robustness of pretrained models, and finally properties that emerge from trained ViTs.

How Neural Radiance Fields (NeRF) and Instant Neural Graphics Primitives work
Explore the basic idea behind neural fields, as well as the two most promising architectures (Neural Radiance Fields (NeRF) and Instant Neural Graphics Primitives)
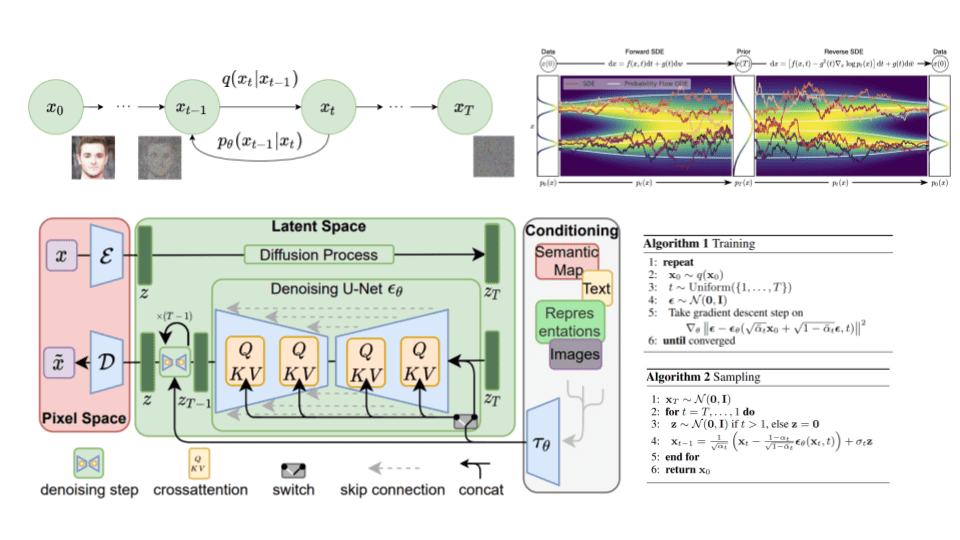
How diffusion models work: the math from scratch
A deep dive into the mathematics and the intuition of diffusion models. Learn how the diffusion process is formulated, how we can guide the diffusion, the main principle behind stable diffusion, and their connections to score-based models.
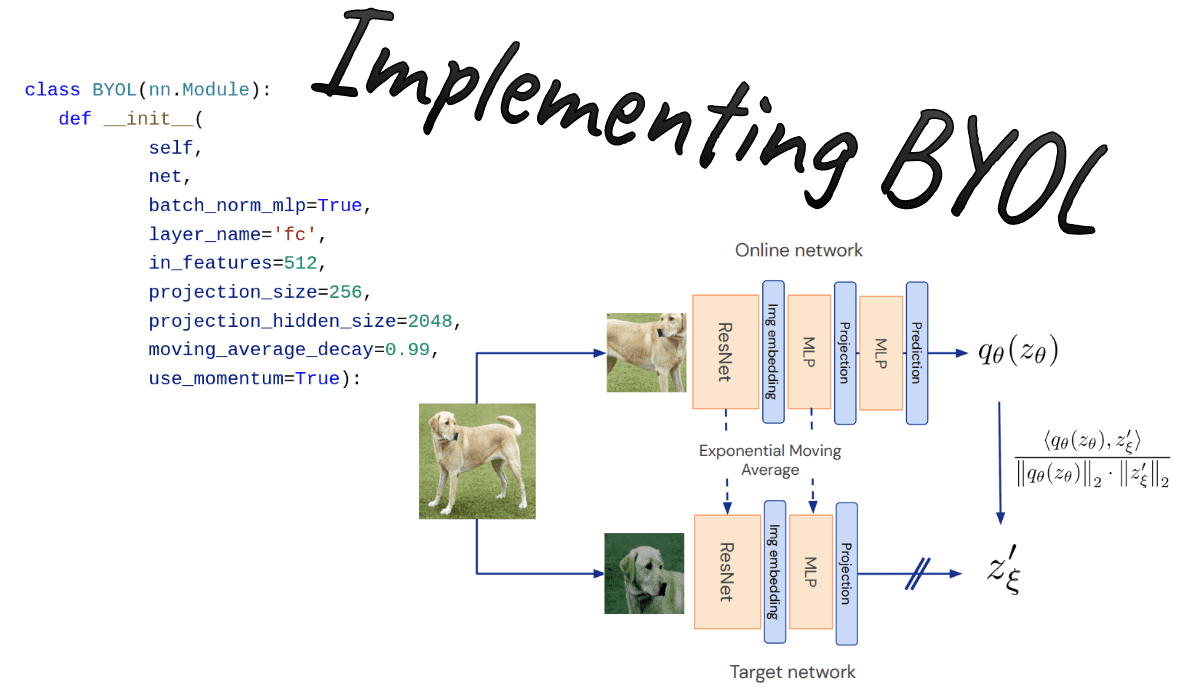
BYOL tutorial: self-supervised learning on CIFAR images with code in Pytorch
Implement and understand byol, a self-supervised computer vision method without negative samples. Learn how BYOL learns robust representations for image classification.
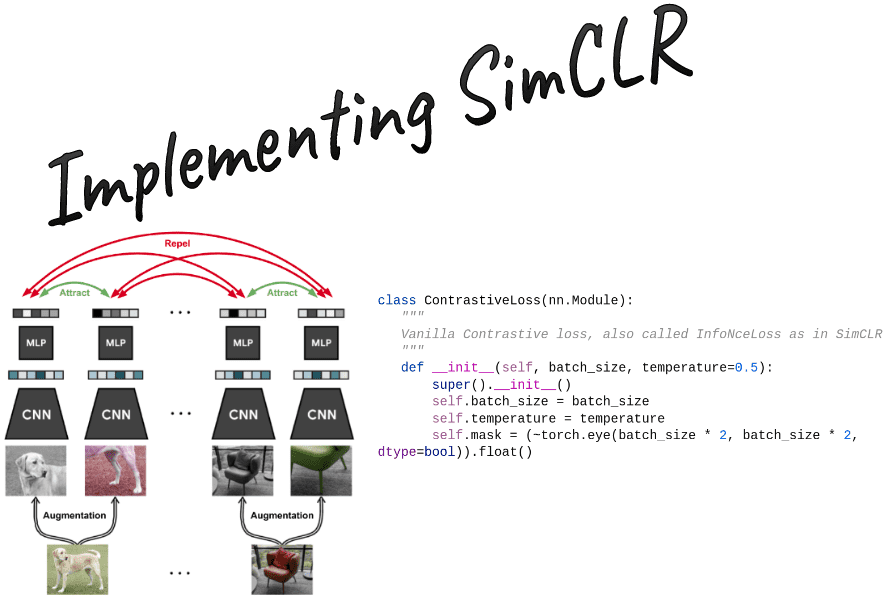
Self-supervised learning tutorial: Implementing SimCLR with pytorch lightning
Learn how to implement the infamous contrastive self-supervised learning method called SimCLR. Step by step implementation in PyTorch and PyTorch-lightning
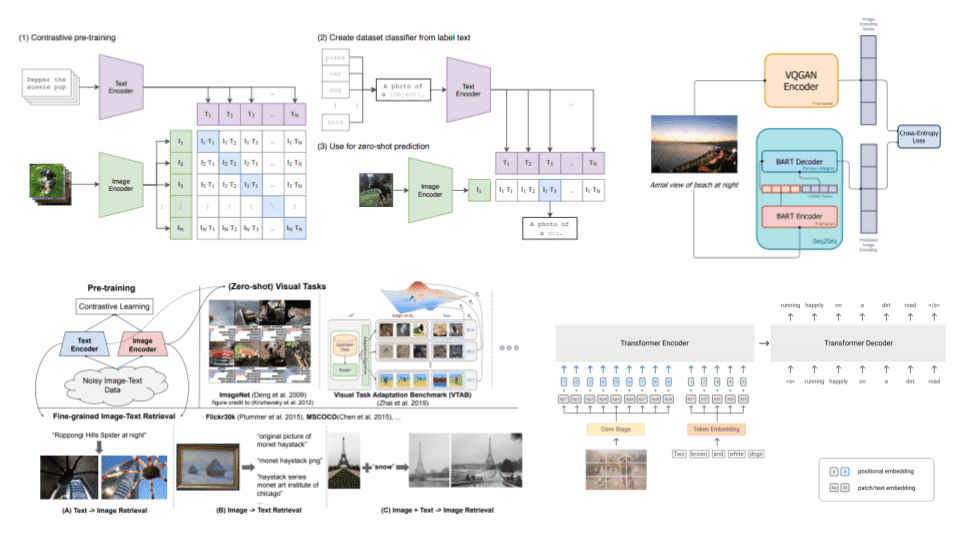
Vision Language models: towards multi-modal deep learning
A review of state of the art vision-language models such as CLIP, DALLE, ALIGN and SimVL
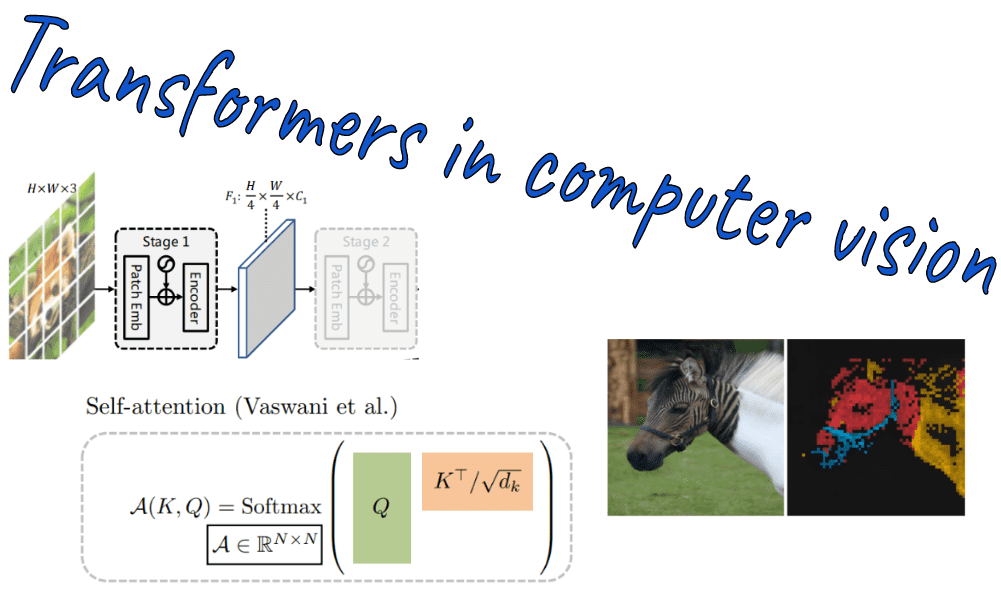
Transformers in computer vision: ViT architectures, tips, tricks and improvements
Learn all there is to know about transformer architectures in computer vision, aka ViT.
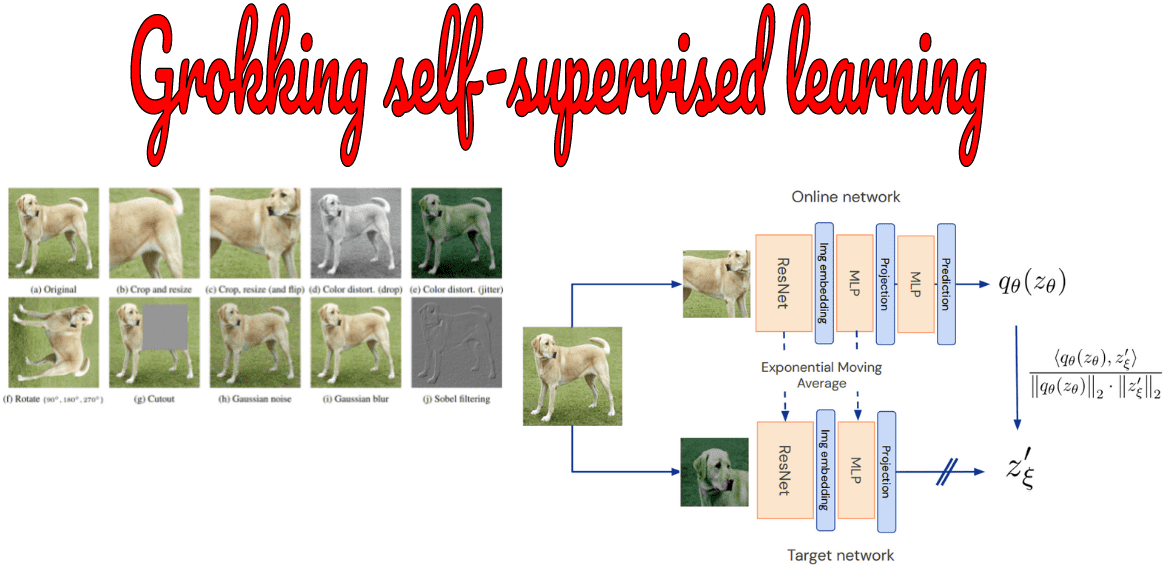
Grokking self-supervised (representation) learning: how it works in computer vision and why
A general perspective on understanding self-supervised representation learning methods.
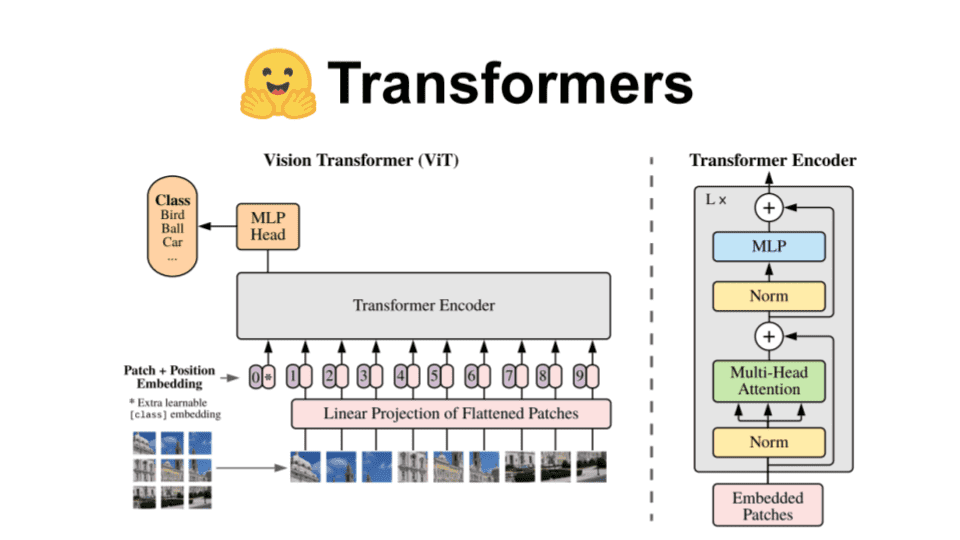
A complete Hugging Face tutorial: how to build and train a vision transformer
Learn about the Hugging Face ecosystem with a hands-on tutorial on the datasets and transformers library. Explore how to fine tune a Vision Transformer (ViT)
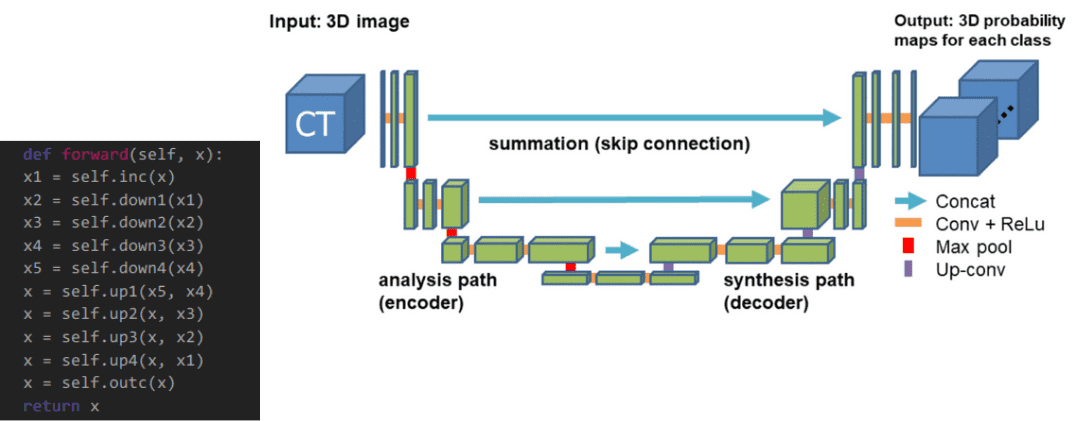
An overview of Unet architectures for semantic segmentation and biomedical image segmentation
Learn everything about one of the most famous convolutional neural network architectures that is widely used on image segmentation.
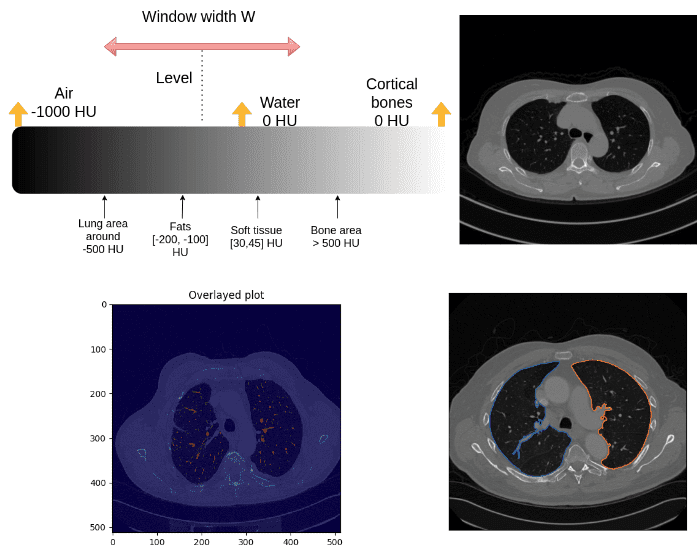
Introduction to medical image processing with Python: CT lung and vessel segmentation without labels
Find out the basics of CT imaging and segment lungs and vessels without labels with 3D medical image processing techniques.
How the Vision Transformer (ViT) works in 10 minutes: an image is worth 16x16 words
In this article you will learn how the vision transformer works for image classification problems. We distill all the important details you need to grasp along with reasons it can work very well given enough data for pretraining.
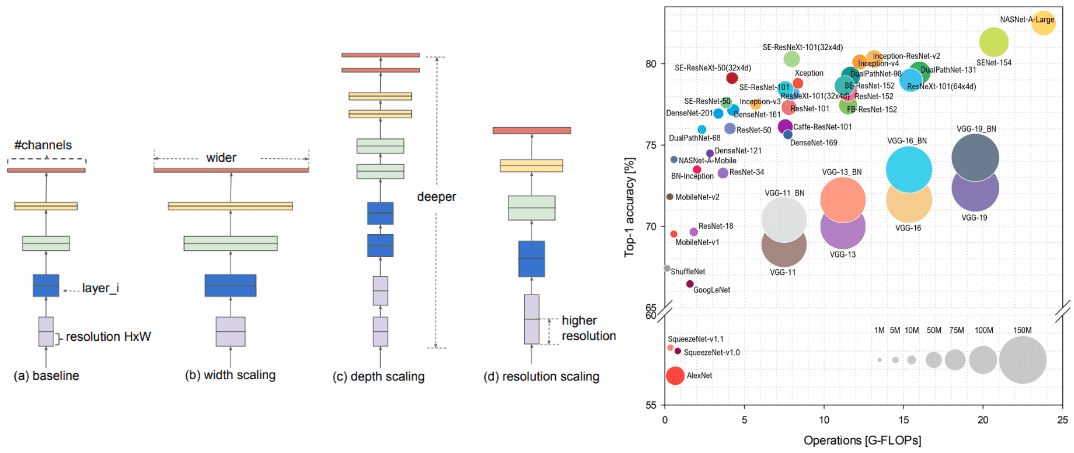
Best deep CNN architectures and their principles: from AlexNet to EfficientNet
How convolutional neural networks work? What are the principles behind designing one CNN architecture? How did we go from AlexNet to EfficientNet?

Transfer learning in medical imaging: classification and segmentation
What is transfer learning? How can it help us classify and segment different types of medical images? Are pretrained computer vision models useful for medical imaging tasks? How is 2D image classification different from 3D MRI segmentation in terms of transfer learning?
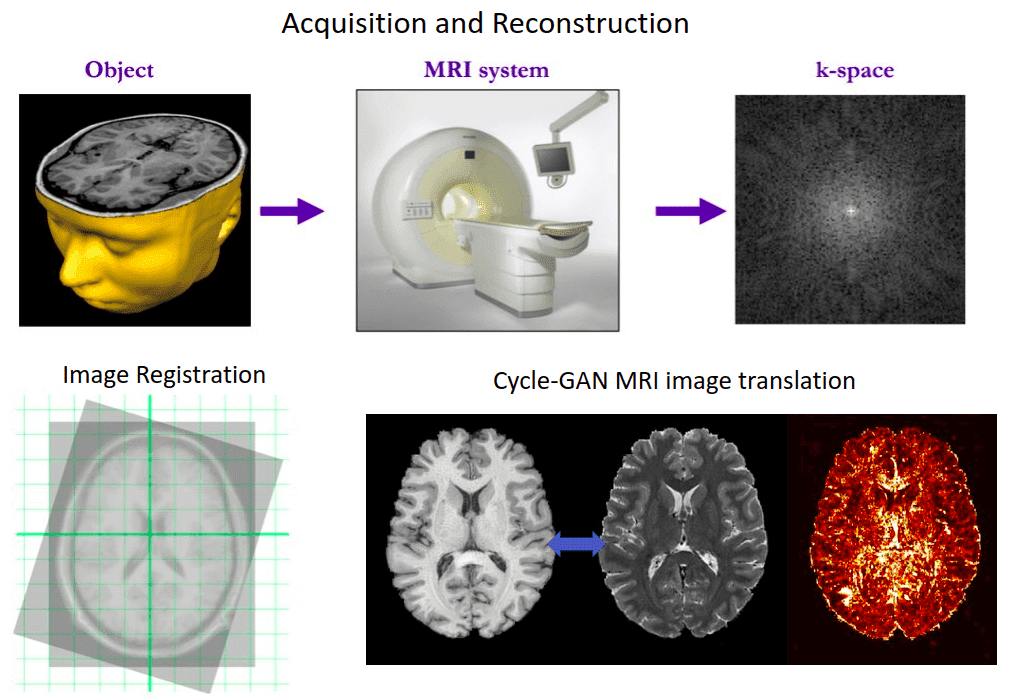
Deep learning in MRI beyond segmentation: Medical image reconstruction, registration, and synthesis
How can deep learning revolutionize medical image analysis beyond segmentation? In this article, we will see a couple of interesting applications in medical imaging such as medical image reconstruction, image synthesis, super-resolution, and registration in medical images

Introduction to 3D medical imaging for machine learning: preprocessing and augmentations
Learn how to apply 3D transformations for medical image preprocessing and augmentation, to setup your awesome deep learning pipeline
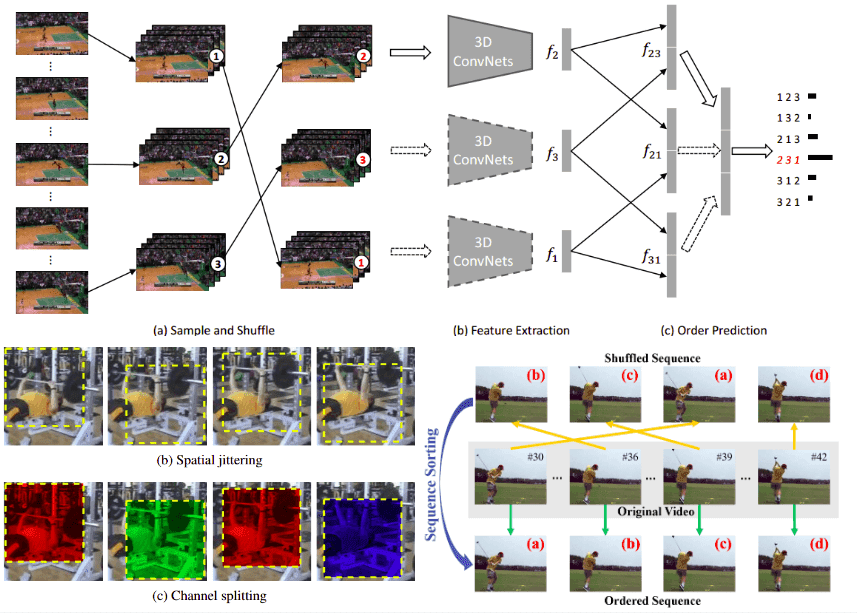
Self-supervised representation learning on videos
In this article, we dive into the state-of-the-art methods on self-supervised representation learning in computer vision, by carefully reviewing the fundamentals concepts of self-supervision on learning video representations.

Understanding coordinate systems and DICOM for deep learning medical image analysis
Multiple introductory concepts regarding deep learning in medical imaging, such as coordinate system and dicom data extraction from the machine learning perspective.
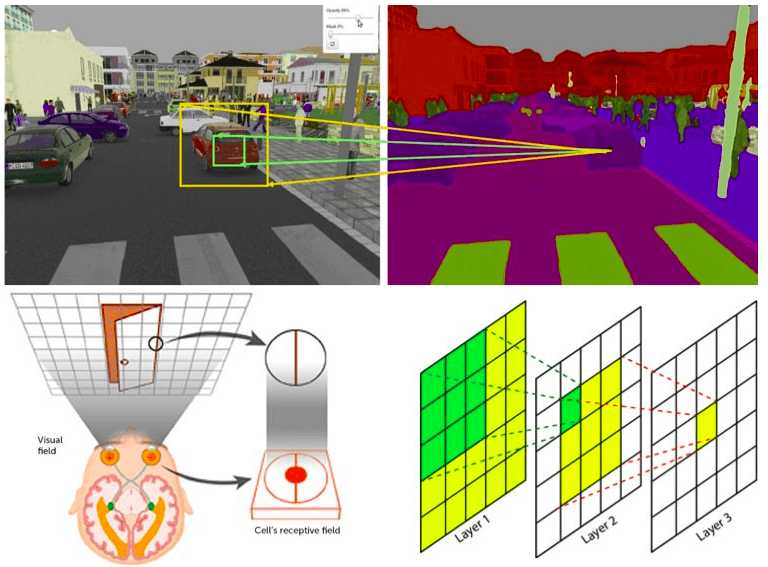
Understanding the receptive field of deep convolutional networks
An intuitive guide on why it is important to inspect the receptive field, as well as how the receptive field affect the design choices of deep convolutional networks.
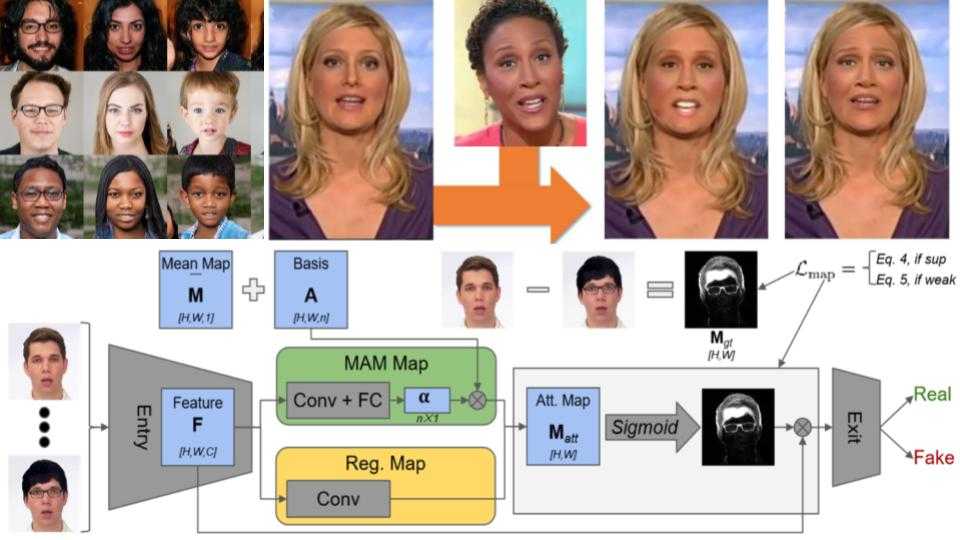
Deepfakes: Face synthesis with GANs and Autoencoders
A closer look on Deepfakes: face sythesis with StyleGAN, face swap with XceptionNet and facial attributes and expression manipulation with StarGAN
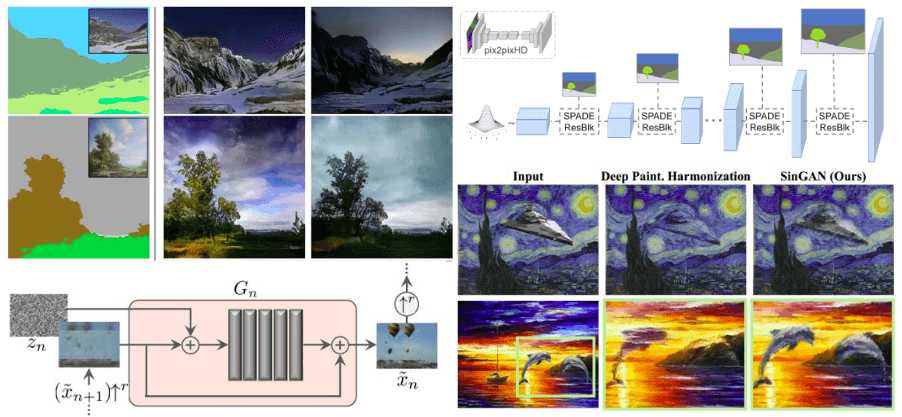
GANs in computer vision - semantic image synthesis and learning a generative model from a single image
The sixth article-series of GAN in computer vision - we explore semantic image synthesis and learning a generative model from a single image

GANs in computer vision - self-supervised adversarial training and high-resolution image synthesis with style incorporation
The fifth article-series of GAN in computer vision - we discuss self-supervision in adversarial training for unconditional image generation as well as in-layer normalization and style incorporation in high-resolution image synthesis.
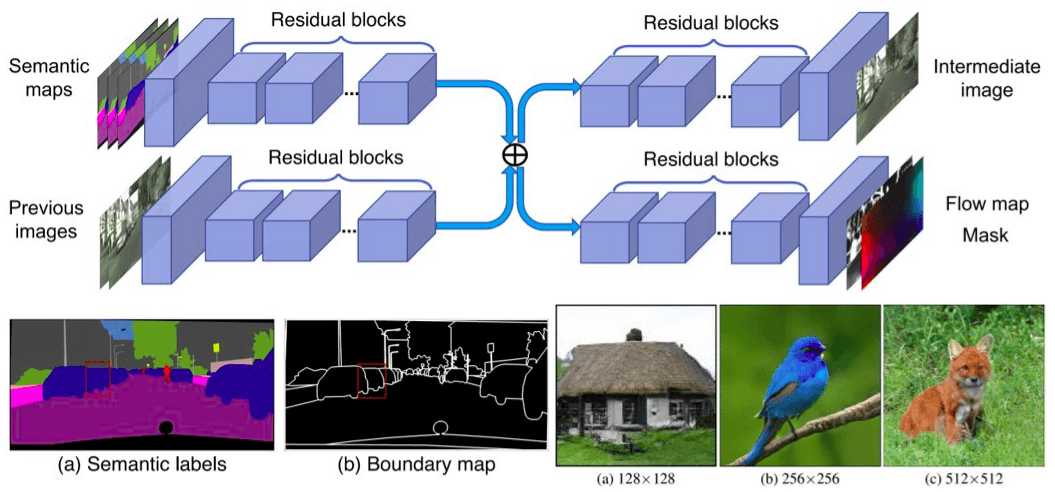
GANs in computer vision - 2K image and video synthesis, and large-scale class-conditional image generation
The fourth article-series of GAN in computer vision - we explore 2K image generation with a multi-scale GAN approach, video synthesis with temporal consistency, and large-scale class-conditional image generation in ImageNet.
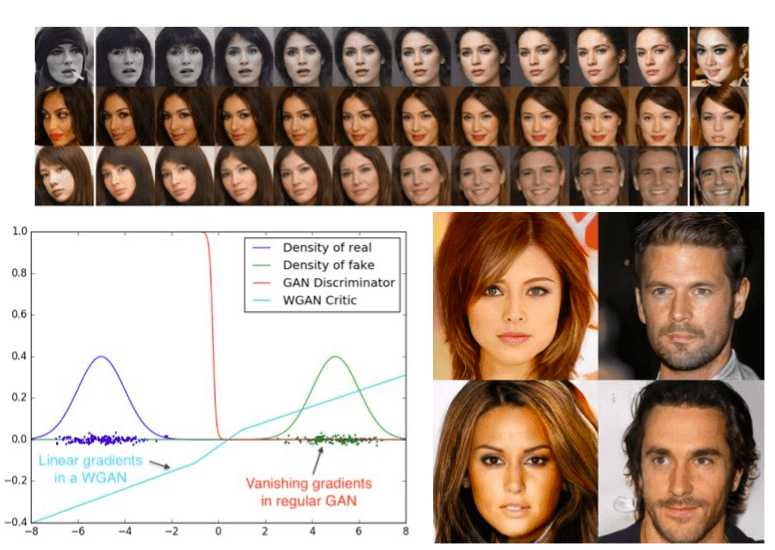
GANs in computer vision - Improved training with Wasserstein distance, game theory control and progressively growing schemes
The third article-series of GAN in computer vision - we encounter some of the most advanced training concepts such as Wasserstein distance, adopt a game theory aspect in the training of GAN, and study the incremental/progressive generative training to reach a megapixel resolution.
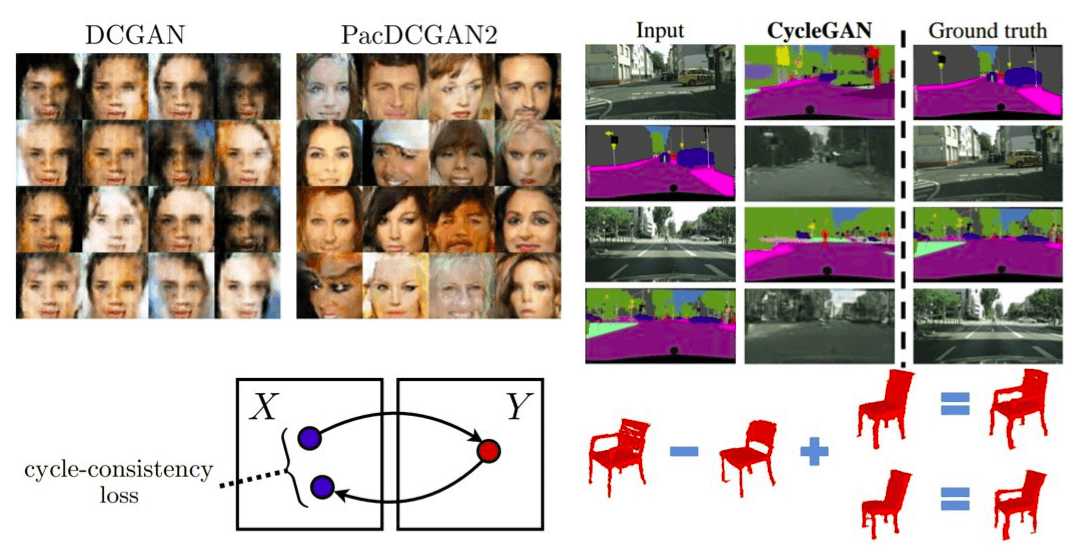
GANs in computer vision - Conditional image synthesis and 3D object generation
The second article of the GANs in computer vision series - looking deeper in generative adversarial networks, mode collapse, conditional image synthesis, and 3D object generation, paired and unpaired image to image generation.
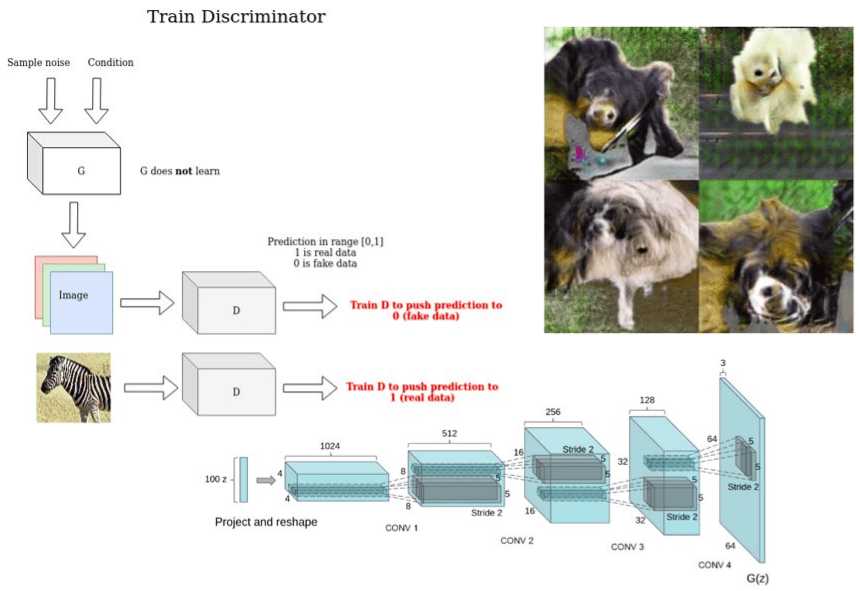
GANs in computer vision - Introduction to generative learning
The first article of the GANs in computer vision series - an introduction to generative learning, adversarial learning, gan training algorithm, conditional image generation, mode collapse, mutual information
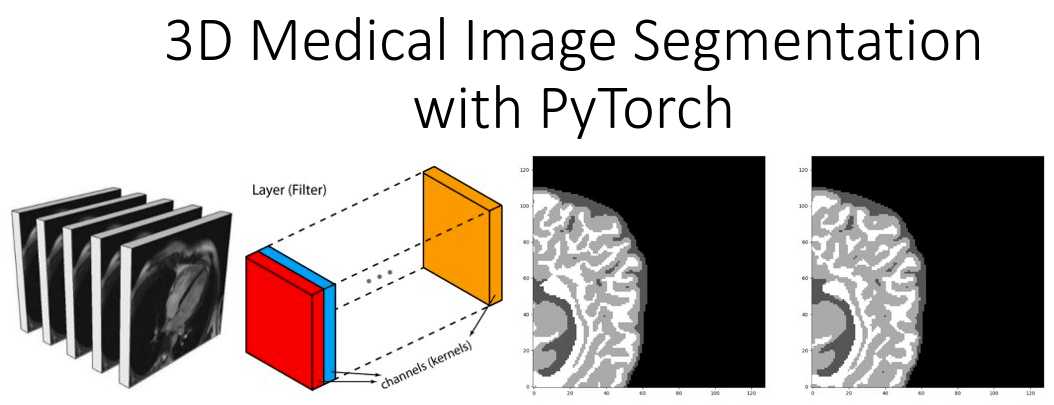
Deep learning in medical imaging - 3D medical image segmentation with PyTorch
The basic MRI foundations are presented for tensor representation, as well as the basic components to apply a deep learning method that handles the task-specific problems(class imbalance, limited data). Moreover, we present some features of the open source medical image segmentation library. Finally, we discuss our preliminary experimental results and provide sources to find medical imaging data.
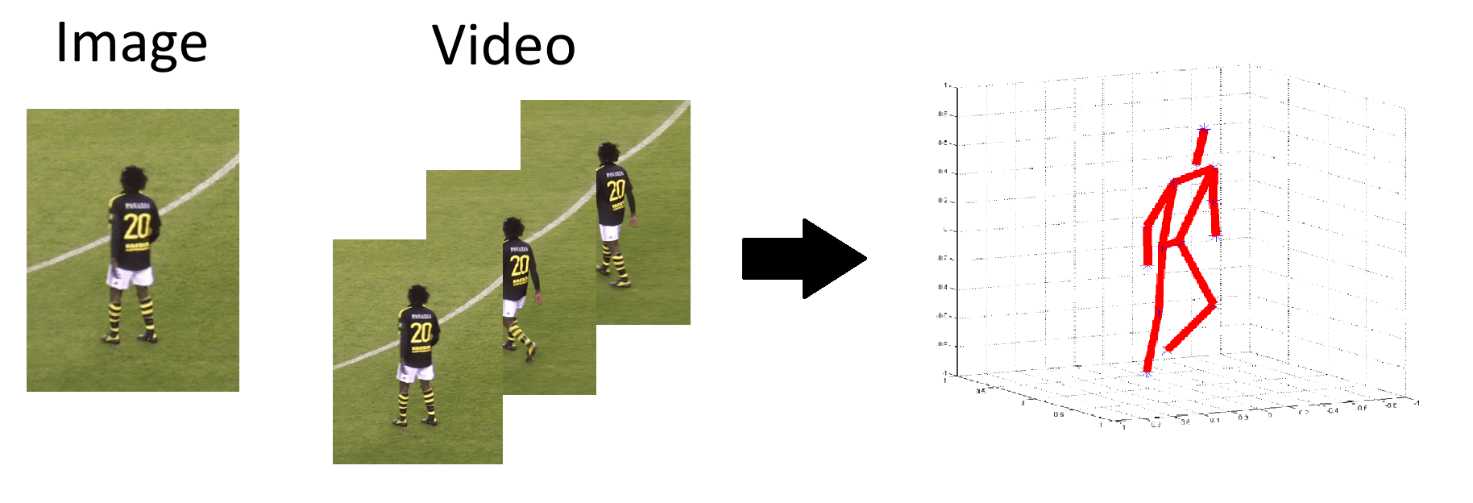
Human Pose Estimation
An overview of the most popular models for performing 2D or 3D Human Pose Estimation

Localization and Object Detection with Deep Learning
Explain RCNN, Fast RCNN and Faster RCNN

Semantic Segmentation in the era of Neural Networks
Semantic segmentation with deep learning
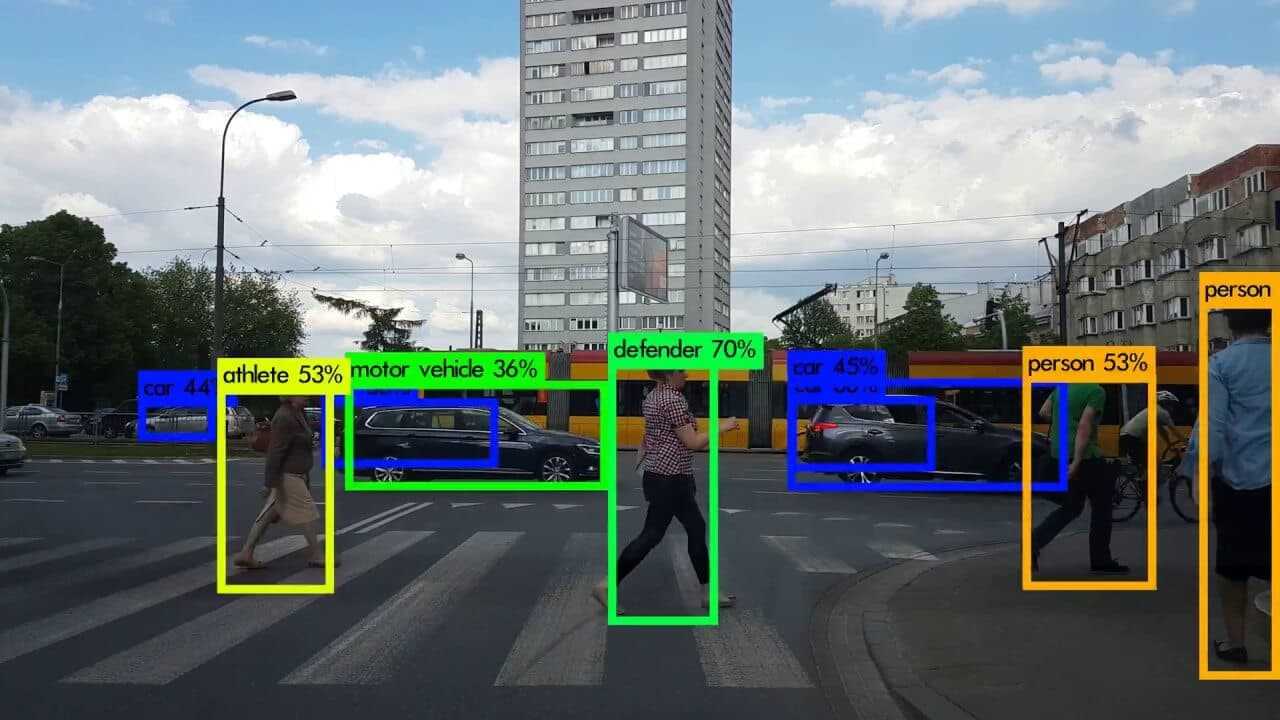
YOLO - You only look once (Single shot detectors)
Single shot detectors and how YOLO is used for object detection and localization
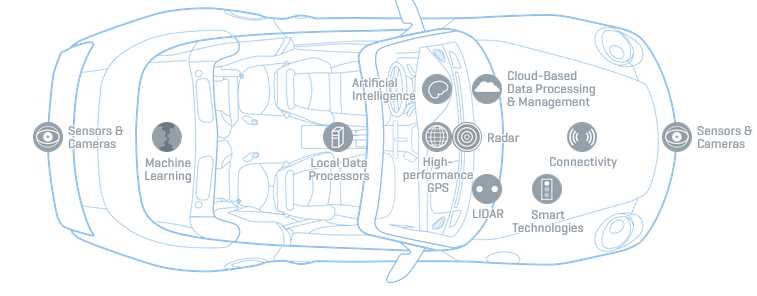
Self-driving cars using Deep Learning
How self driving cars work, why Deep Learning made them a reality and how to program one (sort of)