Nowadays, transfer learning from pretrained models on Imagenet is the ultimate standard in computer vision. Self-supervised learning dominates natural language processing, but this doesn’t mean that there are no significant use-cases for computer vision that it should be considered. There are indeed a lot of cool self-supervised tasks that one can devise when she/he is dealing with images, such as jigsaw puzzles [6], image colorization, image inpainting, or even unsupervised image synthesis.
But what happens when the time dimension comes into play? How can you approach the video-based tasks that you would like to solve?
So, let’s start from the beginning, one concept at a time. What is self-supervised learning? And how is it different from transfer learning? What is a pretext task?
Self-supervised learning VS transfer learning
Transfer learning is a fair point to start.
Transfer learning enables us to exploit the weights of a (convolutional) neural network used for task A and apply it to another task (B), given that the input domains are somehow related.
The training process in task A is called pretraining in machine learning terminology. The core idea behind this is that the acquired ‘knowledge’ of task A may be exploited to enhance generalization in task B. And this is usually the case, because who wants to start from a random weight initialization?
Obviously, transfer learning is one way to maximize the performance of your model, by pretraining on a similar supervised (video) dataset. However, in domains such as videos the problem of annotation (supervision) quickly arises. It is difficult to find video annotated data and transfer weights.
But even before that, let’s clarify the inherent differences of self-supervised learning VS transfer learning. I created this simple diagram to make things crystal clear:
 Self-supervized VS transfer-learning
Self-supervized VS transfer-learning
As a solution to supervision-deprived domains, self-supervised learning is one way to transfer weights, by pretraining your model on labels that are artificially produced from the data/videos.
This can be achieved with a bunch of different (and sometimes tricking) transformations, as we will see. This is exactly what we call self-supervised representation learning.
Note that, for self supervised learning, you can even use just your own data, but without the provided labels
In essence, in self-supervised learning we are trying to guess a related task A so the weight transfer to task B, would be a better initialization point than random.
Notations, concepts and example tasks
The devised self-supervised task A is usually called pretext or proxy task, while the desired task B we want to solve is referred in the literature as a downstream task. I usually refer to it as original task also.
Back in the world of videos, video-based learning fall into the category of sequential learning. These approaches can be broadly divided into two classes: sequence prediction and verification. Additionally, (image) tuples refer to a bunch of frames of a video that will be used as the input to the deep learning architecture. Siamese models or multi-branch models are used interchangeably in the different papers. It is basically independent predictions of multiple input data. You can simply think that a lot of forward passes of the siamese model have to be performed before a backward pass, while the extracted features are fused in the next layers. As a result, the loss that will be backpropagated taken into account all the forward passes.
Now we have a clear high-level concept of self-supervision. Let’s see why it is important, especially on video datasets!
Why Self-Supervised learning?
First of all, you cannot create a new video-dataset (or any kind of dataset) for each particular task. Video annotations are also expensive and time-consuming. Secondly, in a domain such as medical imaging, it is hard to obtain any expert annotation at all. On the other hand, hundreds of thousands of hours of unlabeled videos are uploaded daily on youtube! If you are still not convinced that self-supervised learning is an awesome direction, let’s advise the experts:
“Most of what we learn as humans and most of what animals learn is in a self-supervised mode, not a reinforcement mode. It’s basically observing the world and interacting with it a little bit, mostly by observation in a test-independent way.” ~ Yann LeCun, Director of Facebook AI Research (FAIR)
Now I believe that you are convinced. However, be aware that every exciting idea comes with its assumptions and counterparts. But before that let’s clarify our terminology first.
Moving on, what is the core assumption of self-supervised learning on videos?
Intuitively, we argue that successfully solving the “pretext” task A will allow our model to learn useful visual representation to recover the temporal coherence of a video, or in general learning from the statistical temporal structure of videos.
One example of temporal consistency might be observing how objects (cars, humans) move in the scene.
Some of the questions that may come in your mind, as perfectly described by Misra et al. [1]:
“How does the model learn from the spatiotemporal structure present in the video without using supervised semantic labels?”
“Are the representations learned using the unsupervised/self-supervised spatiotemporal information present in videos meaningful?”
“And finally, are these representations complementary to those learned from strongly supervised image data?”
We will answer these questions by inspecting different approaches.
But even before that, how does one design a self-supervised task?
In short, a good self-supervised task is neither simple nor ambiguous [6].
Another critical factor that we take into account is if humans can solve the pretext task. As an example, try to understand the sequence of the frames below. With a little bit of focus on the relative poses and speculations about “how a person moves”, we can predict the chronological order of these frames.
 Taken from the original work [2]
Taken from the original work [2]
Moreover, we need to choose something that if solved, would require an understanding of our data. That’s why it falls into the category of representation learning anyway :) .
Insight: the key idea is to leverage the inherent structure of raw images and formulate the problem as discriminative (classification) or introduce a reconstruction loss function to train the network.
That being said, I hope you are ready to briefly examine the most influential papers for self-supervised representation learning on videos.
Shuffle and Learn: Unsupervised Learning using Temporal Order Verification, ECCV 2016
This is one of the first works introduced by Misra et al. [1]. They formulate their pretext task as a sequence verification problem.
In (sequential) verification, one predicts the ‘temporal validity’ of the sequence.
In this work, the authors explore the task of whether a sequence of video frames is in the correct temporal order. To do so, they had to use a sampling scheme in order to sample the videos. The reason this is important is of course the computational complexity.
To this end, they sampled images with high motion, based on the mean optical flow magnitude per frame. In order to create positive and negative tuples, samples of five frames were used as an input. Positive samples correspond to the correct order, while negative ones refer to frames in the wrong order. The following image further illustrates the difference.
 An example of video shuffling, positive and negative examples. Taken from the original work [1]
An example of video shuffling, positive and negative examples. Taken from the original work [1]
Training trick: During training, the authors used the same beginning and ending frame, while only changing the middle frame for both positive and negative examples. As a consequence, the network is encouraged to focus on this signal to learn the subtle difference between positives and negatives, rather than irrelevant features.
 An overview of the proposed network architecture of [1]. The image is taken from the original work.
An overview of the proposed network architecture of [1]. The image is taken from the original work.
Based on the architecture scheme, it is worth noting that each frame is processed independently by the AlexNet, while the image features outputs are concatenated for the final classification.
Finally, they used about 900k image tuples, with a balanced mini-batch ratio of positive and negative instances. As it was found out, it is critical to have a larger percentage of negative examples for order verification (75%).
Results and discussion
The question that was posed was what does the model really learn from the temporal structure? In the following image, the authors claim to display the receptive fields (marked in red boxes) for these units. As our network is trained on human action recognition videos, many units show a preference for human body parts and pose, since they are related to high motion. Although it is referenced in the paper as a receptive field the reality is that this is the feature activation of the layer.
 Visualizing activations, taken from [1]
Visualizing activations, taken from [1]
Numerically, by combining this scheme with imagenet pretrained weights, we get almost the same mean accuracy as with supervision from videos, as illustrated below (UCF sup. is the supervised database with action videos):
 Results on action recognition, borrowerd from [1]
Results on action recognition, borrowerd from [1]
Finally, based on the presented results, one can validate that sequence verification requires an understanding of the video-based task at hand (action recognition).
Unsupervised Representation Learning by Sorting Sequences, ICCV 2017
Core contribution: Lee et al 2017 [2] propose an Order Prediction Network (OPN) architecture
to solve the sequence sorting task by pairwise feature extraction.
Extending the previous work, we are trying to sort the shuffled image sequence. If verification requires an understanding of the statistical temporal structure of images, one can probably guess that image sorting will provide richer and more generalizable visual representations. To this end, the authors attempt to train with such a proxy task given a tuple of four sampled images, as illustrated below.
 An example of a sequence sampling and sorting, borrowed from [2]
An example of a sequence sampling and sorting, borrowed from [2]
For a tuple with n frames, there are n! (! is the factorial) possible combinations. In practice, the authors used four randomly shuffled frames. Similar to the jigsaw puzzle problem [6], they cast the problem as multi-class classification. For each tuple of four frames, there are 24 possible permutations. Nevertheless, forward and backward permutations can be casted as one class, as they can be possible solutions to the action, resulting in 12 classes in total.
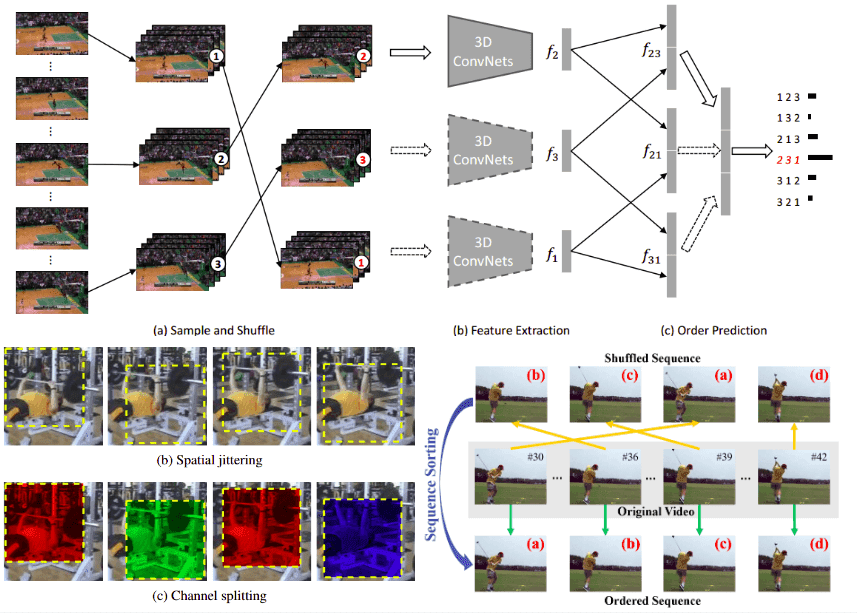
Training data sampling
Similar to other works, they sampled frames based on motion magnitude. In addition to using optical flow magnitude for frame selection only, they further select spatial patches with large motion (a in Figure). Plus, they apply spatial jittering in the already extracted cropped images (shown as b in Figure). Furthermore, they introduce a new tactic called channel splitting (shown as c). This is roughly similar to using grayscale images, but it performs better based on the experimental analysis. Specifically, they choose one channel and duplicate the values to the other two channels of the RGB image. As a result, the network is guided to focus on the semantics of the images, rather than low-level features.
 Training sampling tricks, taken from [2]
Training sampling tricks, taken from [2]
Model architecture, data, and some results
Similar to [1], they produce image features based on a typical convolutional neural network. In literature, this is referred to as Siamese architecture. Again, each frame is processed independently by the same model (usually called multi-branch to be fancier), whereas the parameters are the same. Another important point is the pairwise feature extraction, as shown in the overview of the architecture. As it can be illustrated below, the features of fc6 features are used to form pairs of frame features. These allow some kind of fusion, or in other words to take into account the pairwise relationships of features.
 Siamese model architecture with pairwise feat extraction
Siamese model architecture with pairwise feat extraction
Finally, they extracted 280k tuples from the ~30K UCF-101 action recognition dataset as the training data, with a relatively big batch size of 128. The input patches were 80x80. It is worth noting that one potential reason for the poor performance of using larger patches might be the insufficient amount of training data.
Some illustrations of the feature activations can be seen below. It can be observed that the feature activations correspond to human head and object parts.
 the activation as taken from [2]
the activation as taken from [2]
Self-Supervised Video Representation Learning With Odd-One-Out Networks, CVPR 2017
Let’s start from the task that was devised, called Odd-One-Out. Briefly, the goal of odd-one-out learning is to predict the odd (unrelated) element from a set of otherwise related elements.
Formally, given a set of multiple related elements and only one odd element comprise a question , where are the elements. In this case, are sets of sub-sequences sampled from a video. The described N sub-videos have the correct chronological order. The odd unrelated video sub-sequence is an invalid order from the same video. To prevent a trivial solution, the authors randomize the position of the odd element. As a result, the odd-one-out prediction task is casted as an N+1 classification problem.
Model architecture
The prediction model is a multi-branch CNN, which is called an odd-one-out network (O3N). The O3N is composed of N + 1 input branches, each contains 5 conv. layers (weights are shared across the input layers). The odd-one-out task requires a comparison among (N+1) elements. To solve it, one cannot be looking at the individual elements. Consequently, they further introduce a fusion layer which merges the information from the different branches. Finally, they experimented with two types of fusions, the concatenation, and the sum of difference.
 model o3n overview [3]
model o3n overview [3]
Self-supervised Spatiotemporal Learning via Video Clip Order Prediction, CVPR 2019
Again, Xu et al 2019 [4] formulate the task of order prediction, as a classification problem. In addition to previous works, they integrate 3D CNNs by producing independent features of small video clips rather than pure images. Thus, the task at hand is now called clip order prediction. Their approach can be summarized as follows:
First, several fixed-length (16 frames) clips are sampled from the video and shuffled randomly,
Then, 3D CNNs are used to extract independent features for these clips, using shared weights (siamese architecture).
Finally, a simple neural network is employed to predict the actual order of the shuffled clips.
The learned 3D CNNs can be either used as a clip feature extractor or a pre-trained model to be fine-tuned to action recognition. To prove their ideas, three powerful 3D-CNN architectures are evaluated, namely C3D [9], R3D, and R(2+1)D [10] (denoted as 3D ConvNets in the image below). An overview of the proposed architecture can be depicted below:
 The proposed model architecture [4]
The proposed model architecture [4]
Note: Since clip order prediction is just a proxy task and the goal is to learn video representations, the task should be solvable. For tuple length, 3 clips per tuple are chosen, with a batch size of 8 tuples. The video clip consists of 16 frames for the 3D CNNs, while the interval between videos is set to be 8 frames, to avoid trivial solutions.
In order to validate the learned representations, they use the nearest neighbor retrieval based on the produced features from the 3D-CNNs. To evaluate their approach to action recognition, 10 clips are sampled from the video to get clip predictions, which are then averaged to obtain the final video prediction.
As a final note, while this study shows promising results, the finetuning from supervised pre-training on larger datasets such as Kinetics still acts as the best pretraining scheme.
Conclusion
I hope you get the idea by now. We are going to see more and more cool applications of self-supervised learning. To briefly summarize, we had our little dive in self-supervised learning, focusing on videos. We introduced the problems that arise with the additional time dimension and how one can cope with them. Based on the presented works, here are my closing conclusion points:
TL;DR
A good-designed self-supervised task is neither simple nor ambiguous. A human must be able to solve it, and the pretext task optimization must require an understanding of our data for our original/downstream task.
We argue that successfully solving the “pretext” task will allow our model to learn useful visual representation to recover the temporal coherence of a video.
In videos, sequence sampling is really important, as well as training tricks (i.e. channel splitting, same start & and frame etc.)
The core idea is to leverage the inherent structure of raw/unlabeled data and formulate a supervised problem, usually classification.
Independent feature extraction is applied in the sequence’s elements (referred as siamese re shared weight networks or multi-branch models).
These independent features are usually processed with fully connected layers, where pairwise matching and feature differences seems to work better than simple concatenation.
As additional material, an inspiring presentation that is really worth watching is again by Yann LeCun in ICLR 2020. The positive side of virtual conferences I guess. I really enjoyed watching this one.
For those who want something more advanced you can move on to Self-Supervised Generative Adversarial Networks, as you know how much we like generative learning in AI summer. Finally, for a more comprehensive approach to a summary of a plethora of self-supervised representation learning (not focused on videos), check out this blog post [8] by Lilian Weng.
Cited as:
@article{adaloglou2020sslv,title = "Self-supervised representation learning on videos",author = "Adaloglou, Nikolas",journal = "https://theaisummer.com/",year = "2020",url = "https://theaisummer.com/self-supervised-learning-videos/"}
References
[1] Misra, I., Zitnick, C. L., & Hebert, M. (2016, October). Shuffle and learn: unsupervised learning using temporal order verification. In European Conference on Computer Vision (pp. 527-544). Springer, Cham.
[2] Lee, H. Y., Huang, J. B., Singh, M., & Yang, M. H. (2017). Unsupervised representation learning by sorting sequences. In Proceedings of the IEEE International Conference on Computer Vision (pp. 667-676).
[3] Fernando, Basura, et al. "Self-supervised video representation learning with odd-one-out networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[4] Xu, D., Xiao, J., Zhao, Z., Shao, J., Xie, D., & Zhuang, Y. (2019). Self-supervised spatiotemporal learning via video clip order prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 10334-10343).
[5] Jiao, J., Droste, R., Drukker, L., Papageorghiou, A. T., & Noble, J. A. (2020, April). Self-Supervised Representation Learning for Ultrasound Video. In 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI) (pp. 1847-1850). IEEE.
[6] Noroozi, M., & Favaro, P. (2016, October). Unsupervised learning of visual representations by solving jigsaw puzzles. In European Conference on Computer Vision (pp. 69-84). Springer, Cham.
[7] Gopnik, A., Meltzoff, A. N., & Kuhl, P. K. (2000). The scientist in the crib: What early learning tells us about the mind. William Morrow Paperbacks.
[8][self supervised representation learning](https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html), Weng, Lilian 2019
[9] Tran, D., Bourdev, L., Fergus, R., Torresani, L., & Paluri, M. (2015). Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE international conference on computer vision (pp. 4489-4497).
[10] Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., & Paluri, M. (2018). A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (pp. 6450-6459).

* Disclosure: Please note that some of the links above might be affiliate links, and at no additional cost to you, we will earn a commission if you decide to make a purchase after clicking through.