Recently, fake news have become a major threat to human society. False information can be spread fast through social media and can affect decision making. Moreover, it is challenging even for recent AI technologies to recognize fake data. One of the most recent developments in data manipulation is well-known as “Deepfake”, which refers to the swap of faces in images or videos. So far, deepfake techniques have mostly been applied by swapping celebrity faces in funny videos or by making politicians saying hilarious dumb speeches. However, many industries could benefit from deepfake applications such as the film industry by using advanced video editing.
How do DeepFakes work?
Let’s have a closer look at how Deepfakes work. Deepfakes are usually based on Generative Adversarial Networks (GANs), where two competing neural networks are jointly trained. GANs have had significant success in many computer vision tasks. They were introduced in 2014 and modern architectures are capable of generating realistic-looking images that even a human can’t recognize whether it’s real or not. Below you can see some images from a successful GAN model called StyleGAN.

These people are not real – they were produced by StyleGAN’s generator that allows control over different aspects of the image.
What is Deepfakes?
Based on Wiki, Deepfakes are synthetic media in which a person in an existing image or video is replaced with someone else's likeness. The act of injecting a fake person in an image is not new. However, recent Deepfakes methods usually leverage the recent advancements of powerful GAN models, aiming at facial manipulation.
In general, facial manipulation is usually conducted with Deepfakes and can be categorized in the following categories:
Face synthesis
Face swap
Facial attributes and expression
Face synthesis
In this category, the objective is to create non-existent realistic faces using GANs. The most popular approach is StyleGAN. Briefly, a new generator architecture learns separation of high-level attributes (e.g., pose and identity when trained on human faces) without supervision and stochastic variation in the generated images (e.g., freckles, hair), and it enables intuitive, scale-specific control of the synthesis. The StyleGAN’s generator is shown in Figure 2.
The input is mapped through several fully connected layers to an intermediate representation w which is then fed to each convolutional layer through adaptive instance normalization (AdaIN), where each feature map is normalized separately. Gaussian noise is added after each convolution. The benefit of adding noise directly in the feature maps of each layer is that global aspects such as identity and pose are unaffected.
The StyleGAN generator architecture makes it possible to control the image synthesis via scale-specific modifications to the styles. The mapping network and affine transformations are a way to draw samples for each style from a learned distribution, and the synthesis network is a way to generate an image based on a collection of styles. The effects of each style are localized in the network, i.e., modifying a specific subset of the styles can be expected to affect only certain aspects of the image. The reason for this localization,, is based on the AdaIN operation that first normalizes each channel to zero mean and unit variance, and only then applies scales and biases based on the style. The new per-channel statistics, as dictated by the style, modify the relative importance of features for the subsequent convolution operation, but they do not depend on the original statistics because of the normalization. Thus each style controls only oneconvolution before being overridden by the next AdaIN operation.
 StyleGAN’s generator architecture
StyleGAN’s generator architecture
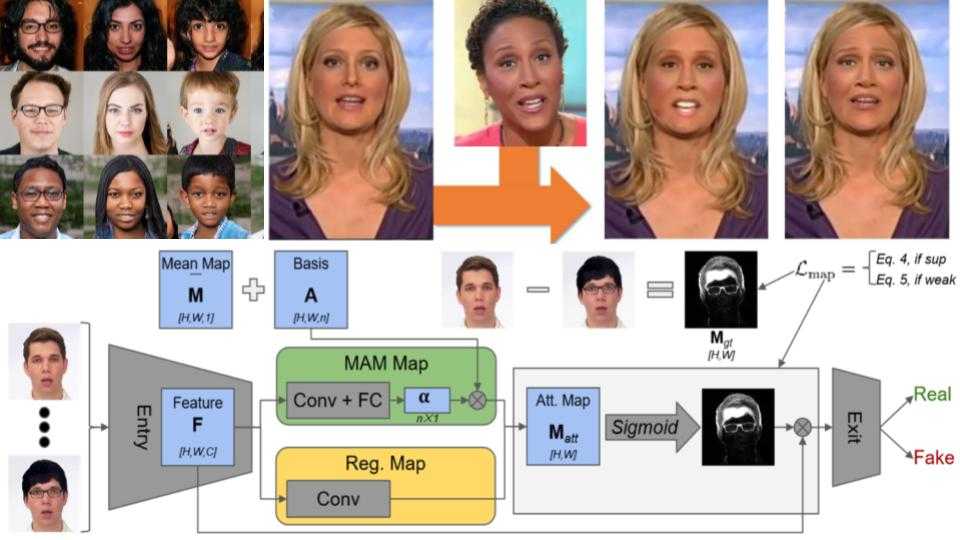
In order to detect fake synthetic images, various approaches have been produced. For example, in the work On the Detection of Digital Face Manipulation, the authors used attention layers on top of feature maps to extract the manipulated regions of the face. Their network outputs a binary decision about whether an image is real or fake.
 The attention-based face manipulation detection method.
The attention-based face manipulation detection method.
The architecture of the face manipulation detection can use any backbone network and the attention-based layer can be inserted into the network. It takes the high-dimensional feature F input, estimates an attention map M_att using either Manipulation Appearance Model (MAM)-based or regression-based methods, and channel-wise multiplies it with the high-dimensional features, which are fed back into the backbone. The MAM method assumes that any manipulated map can be represented as a linear combination of a set of map prototypes while the regression method estimates the attention map via a convolutional operation. In addition to the binary classification loss, either a supervised or weakly supervised loss, L_map can be applied to estimate the attention map, depending on whether the ground truth manipulation map M_gt is available.
Face swap
Face swap is the most popular face manipulation category nowadays. The aim here is to detect whether an image or video of a person is fake after swapping its face. The most popular database with fake and real videos is FaceForensics++. The fake videos in this dataset were made using computer graphics (FaceSwap) and deep learning methods (DeepFake FaceSwap). The FaceSwap app is written in Python and uses face alignment, Gauss-Newton optimization, and image blending to swap the face of a person seen by the camera with a face of a person in a provided image. ( for further details check the official repo )
The DeepFake FaceSwap approach is based on two autoencoders with a shared encoder that are trained to reconstruct training images of the source and the target face, respectively.
A face in a target sequence is replaced by a face that has been observed in a source video or image collection. A face detector is used to crop and to align the images. To create a fake image, the trained encoder and decoder of the source face are applied to the target face. The autoencoder output is then blended with the rest of the image using Poisson image editing.
 Example of face swap, taken from here
Example of face swap, taken from here
The detection of swapped faces is now continuously evolving since it is very important in safeguarding human rights. AWS, Facebook, Microsoft, the Partnership on AI’s Media Integrity Steering Committee, and academics have come together to build the Deepfake Detection Challenge (DFDC) in Kaggle with 1,000,000 $ prizes in total. The goal of the challenge is to spur researchers around the world to build innovative new technologies that can help detect Deepfakes and manipulated media. Most face swap detection systems use Convolutional Neural Networks (CNNs) trying to learn discriminative features or recognize “fingerprints” that are left from GAN-synthesized images. Extensive experiments were conducted from Rössler et. al with five network architectures.
a CNN-based system trained through handcrafted features
a CNN-based system with convolution layers that try to suppress the high-level content of the image
a CNN-based system with a global pooling layer that computes four statistics (mean, variance, maximum, and minimum)
the CNN MesoInception-4 detection system
the CNN-based system XceptionNet pre-trained using ImageNet dataset and trained again for the face swap task. XceptionNet is a CNN architecture inspired from Inception and uses depth-wise separable convolutions
XceptionNet achieved the best results in face swap detection among these five architectures in detecting fake images. It’s superiority in performance is heavily based in depthwise convolutions.
 XceptionNet architecture taken from the original work
XceptionNet architecture taken from the original work
Facial attributes and expression
Facial attributes and expression manipulation consist of modifying attributes of the face such as the color of the hair or the skin, the age, the gender, and the expression of the face by making it happy, sad, or angry. The most popular example is the FaceApp mobile application that was recently launched. The majority of those approaches adopt GANs (what else?) for image-to-image translation. One of the best performing methods is StarGAN that uses a single model trained across multiple attributes’ domains instead of training multiple generators for every domain. A detailed analysis is provided here.
 Example of facial attributes manipulation, borrowed from here
Example of facial attributes manipulation, borrowed from here
 StarGAN’s general architecture, taken from the original work
StarGAN’s general architecture, taken from the original work
The StarGAN consists of a discriminator D and a generator G. The discriminator tries to predict whether an input image is fake or real and classifies the real image to its corresponding domain. The generator takes in as input both the image and target domain label and generates a fake image. The target domain label is spatially replicated and concatenated with the input image. Then, the generator tries to reconstruct the original image from the fake image given the original domain label. Finally, the generator G tries to generate images indistinguishable from real images and classifiable as target domain by the discriminator.
Finally, you can watch this video to maximize your understanding:
Conclusion
In this article, motivated by the recent development on Deepfakes generation and detection methods, we discussed the main representative face manipulation approaches. For further information about Deepfakes datasets, as well as generation and detection methods, you can check out my github repo. We tried to collect a curated list of resources regarding Deepfakes.
References
Karras, T., Laine, S., & Aila, T. (2019). A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 4401-4410).
Tolosana, R., Vera-Rodriguez, R., Fierrez, J., Morales, A., & Ortega-Garcia, J. (2020). Deepfakes and Beyond: A Survey of Face Manipulation and Fake Detection. arXiv preprint arXiv:2001.00179.
Chollet, F. (2017). Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1251-1258).
Choi, Y., Choi, M., Kim, M., Ha, J. W., Kim, S., & Choo, J. (2018). Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 8789-8797).
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680).
Afchar, D., Nozick, V., Yamagishi, J., & Echizen, I. (2018, December). Mesonet: a compact facial video forgery detection network. In 2018 IEEE International Workshop on Information Forensics and Security (WIFS) (pp. 1-7). IEEE.
Rossler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., & Nießner, M. (2019). Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE International Conference on Computer Vision (pp. 1-11).

* Disclosure: Please note that some of the links above might be affiliate links, and at no additional cost to you, we will earn a commission if you decide to make a purchase after clicking through.