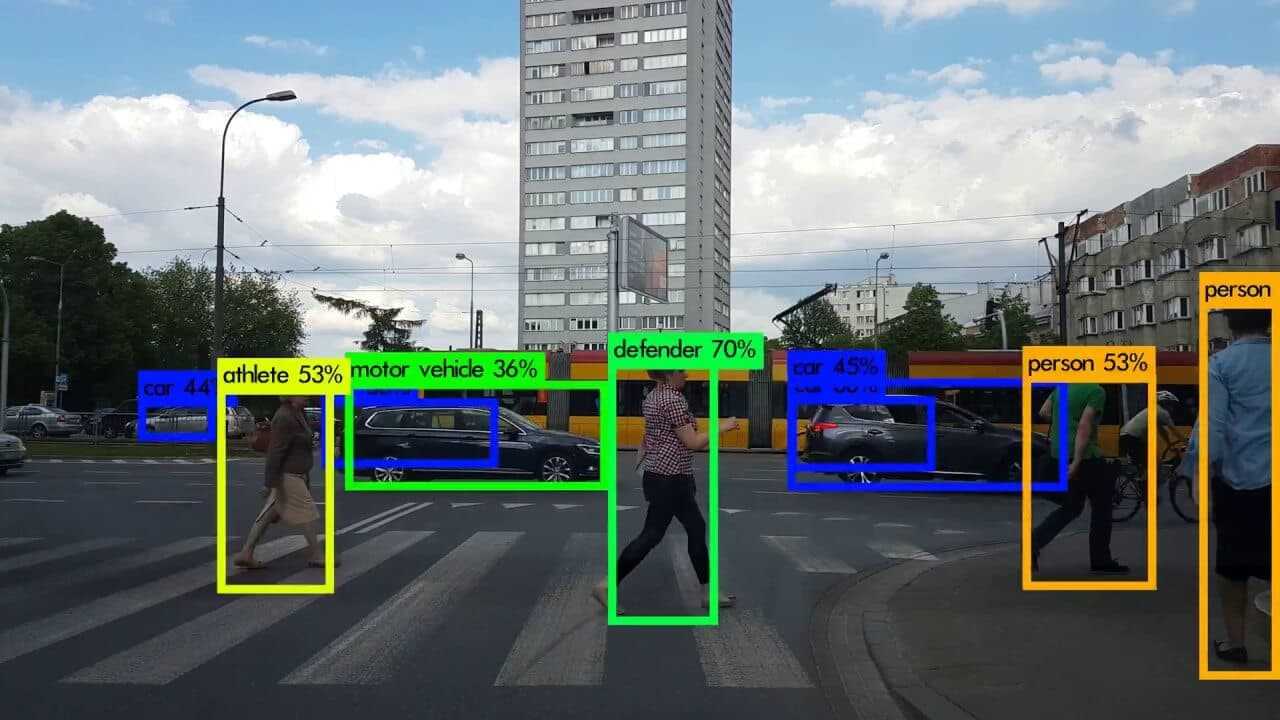
YOLO!!! So do we only live once? I sure do not know. What I know is that we only have to LOOK once. Wait what?
That’s right. If you want to detect and localize objects in an image, there is no need to go through the whole process of proposing regions of interest, classify them and correct their bounding boxes. If you recall from my previous article, this is exactly what models like RCNN and Faster RCNN do.
Do we really need all that complexity and computation? Well if we want top-notch accuracy we certainly do. Luckily there is another simpler way to perform such a task, by processing the image only once and output the prediction immediately. These types of models are called Single shot detectors.
 https://github.com/karolmajek/darknet-pjreddie
https://github.com/karolmajek/darknet-pjreddie
Single shot detectors
Instead of having a dedicated system to propose regions of interests, we have a set of predefined boxes to look for objects, which are forwarded to a bunch of convolutional layers to predict class scores and bounding box offsets. Then for each box we predict a number of bounding boxes with a confidence score assigned to each one, we detect one object centered in that box and we output a set of probabilities for each possible class. Once we have all that, we simply and maybe naively keep only the box with a high confidence score. And it works. With very impressive results actually. To elaborate the overall flow even better, let’s use one of the most popular single shot detectors called YOLO .
You only look once (YOLO)
There have been 3 versions of the model so far, with each new one improving the previous in terms of both speed and accuracy. The number of predefined cells and the number of predicted bounding boxes for each cell is defined based on the input size and the classes. In our case, we are going to use the actual numbers used to evaluate the PASCAL VOC dataset.
First, we divide the image into a grid of 13x13, resulting in 169 cells in total.
For every one of the cells, it predicts 5 bounding boxes (x,y,w,h) with a confidence score, it detects one object regardless the number of boxes and 20 probabilities for the 20 classes.
In total, we have 169*5=845 bounding boxes and the shape of output tensor of the mode is going to be (13,13,5*5+20)= (13,13,45). The whole essence of the YOLO models is to build this (13,13,45) tensor. To accomplish that, it uses a CNN network and 2 fully connected layers to perform the actual regression.
The final prediction is extracted after keeping only the bounding boxes with a high confidence score( higher than a threshold such as 0.3)
 https://pjreddie.com/darknet/yolo/
https://pjreddie.com/darknet/yolo/
Because the model may output duplicate detections for the same object, we use a technique called Non-maximal suppression to remove duplicates. In a simple implementation, we sort the predictions by the confidence score and as we iterate them we keep only the first appearances of each class.
As far as the actual model is concerned, the architecture is quite trivial as it consists of only convolutional and pooling layers, without any fancy tricks. We train the model using a multiple loss function, which includes a classification loss, a localization loss and a confidence loss.
 Object Detection with Deep Learning: A Review
Object Detection with Deep Learning: A Review
The most recent versions of YOLO have introduced some special tricks to improve the accuracy and reduce the training and inference time. Some examples are batch normalization, anchor boxes, dimensions clusters and others. If you want to get into more details, you should definitely check the original papers.
Also to dive into code and try the YOLO models in practice, check out these two awesome repositories in Github (repo1 and repo2).
The power of YOLO is not its spectacular accuracy or the very clever ideas behind it, is its superb speed, which makes it ideal for embedded systems and low-power applications. That’s why self-driving cars and surveillance cameras are its most common real-world use cases.
As deep learning continues to play along with computer vision (and it will sure do), we can expect many more models to be tailored for low-power systems even if they sometimes sacrify accuracy. And dont forget the whole Internet of Things kind of thing. This is where these models really shine.

* Disclosure: Please note that some of the links above might be affiliate links, and at no additional cost to you, we will earn a commission if you decide to make a purchase after clicking through.