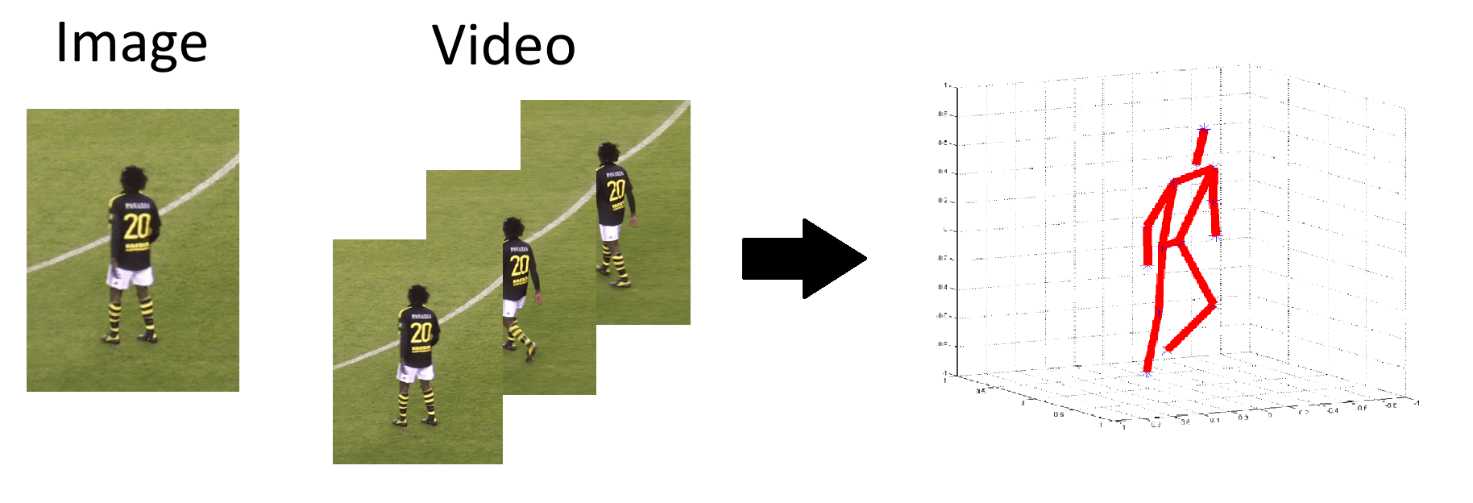
Human Pose Estimation is an important task in Computer Vision which has gained a lot of attention the last years and has a wide range of applications like human-computer interaction, gaming, action recognition, computer-assisted living, special effects. It has rapidly progressed with the advent of neural networks in the deep learning era.
 Figure 1 HPE
Figure 1 HPE
So, what is Human Pose Estimation?
The goal of 3D human pose estimation is to estimate the joints location of one or more human bodies in 2D or 3D space from a single image. Joints are connected to form a skeleton to describe the pose of the person.
We will focus on the most popular and recent works on 2D and 3D Human Pose Estimation
OpenPose
 Figure: The overall architecture of OpenPose
Figure: The overall architecture of OpenPose
OpenPose is the most popular open-source tool for body, foot, hand, and facial keypoint detection. It makes use of Part Affinity Fields (PAFs), a set of 2D vector fields to encode the location and orientation of limbs over the image domain. As shown in the image F is passed through several convolutional layers to generate the the PAFs (L) and confidence maps S for every joint location. The process is repeated for some iterations and the network refines its predictions at every stage. OpenPose is still widely used in many research projects.
A simple yet effective baseline for 3d human pose estimation
 Figure 3: A diagram of our approach. The building block of our network is a linear
layer, followed by batch normalization, dropout and a RELU activation. This is
repeated twice, and the two blocks are wrapped in a residual connection. The
outer block is repeated twice. The input to our system is an array of 2d joint
positions, and the output is a series of joint positions in 3d
Figure 3: A diagram of our approach. The building block of our network is a linear
layer, followed by batch normalization, dropout and a RELU activation. This is
repeated twice, and the two blocks are wrapped in a residual connection. The
outer block is repeated twice. The input to our system is an array of 2d joint
positions, and the output is a series of joint positions in 3d
In this work the authors implemented a lightweight and fast network able to process 300 frames per second!!! After extracting 2d joint location, due to the low dimensionality of 2d space, they use a simple neural network as shown in the next Figure which has a small number of parameters and can be easily trained. The network is trying to estimate the coordinates of joints in 3d space.
DensePose: Dense Human Pose Estimation In The Wild
DensePose adopts the architecture
of Mask-RCNN with the Feature Pyramid
Network
(FPN)
features, and ROI-Align pooling so as to obtain dense part labels and
coordinates within each of the selected regions.
As shown below, the method adopts a fully-convolutional
network
on top of the ROI-pooling that is entirely devoted to generating per-pixel
classification results for selection of surface part and regressing local
coordinates within each part.

The DensePose-RCNN system can be trained directly using the annotated points as supervision. However, we obtain substantially better results by ‘inpainting’ the values of the supervision signal on positions that are not originally annotated. To achieve this, we adopt a learning-based approach is adopted, where a ‘teacher’ network is trained at first: A fully-convolutional neural network that reconstructs the ground-truth values given images scale-normalized images and the segmentation masks.
VIBE: Video Inference for Human Body Pose and Shape Estimation

The VIBE framework is trained to predict human pose and shape in video (image sequences) instead of images. Using a temporal network it produces kinematically plausible human motion. They leverage two sources of unpaired information by training a sequence-based generative adversarial network (GAN). Given the video of a person, a temporal model is trained to predict the parameters of the SMPL body model for each frame while a motion discriminator tries to distinguish between real and regressed sequences. A CNN extracts features for each frame which are passed from gated recurrent units to model the motion. These features are used to estimate the body model parameters. The estimated body model and samples from a motion capture dataset are given to the discriminator to distinguish between fake and real examples.
Multi-task Deep Learning for Real-Time 3D Human Pose Estimation and Action
 Figure The proposed multi-task approach for human pose estimation and action
recognition. This method provides 2D/3D pose estimation from single images or
frame sequences. Pose and visual information are used to predict actions in a
unified framework and both predictions are refined by K prediction blocks
Figure The proposed multi-task approach for human pose estimation and action
recognition. This method provides 2D/3D pose estimation from single images or
frame sequences. Pose and visual information are used to predict actions in a
unified framework and both predictions are refined by K prediction blocks
A multi-task framework is trained for jointly estimating 2D or 3D human poses from monocular colour images and classifying human actions from video sequences
 Figure Overview of the multi-task network architecture
Figure Overview of the multi-task network architecture
Input images are fed through the entry-flow, which extracts low level visual features. The extracted features are then processed by a sequence of downscaling and upscaling pyramids indexed by p Each Prediction Block (PB) is supervised on pose and action predictions, which are then re-injected into the network, producing a new feature map that is refined by further downscaling and upscaling pyramids
This flexible network architecture can inference individual frames for pose estimation or entire video for action recognition.
Learnable Triangulation of Human Pose
 Figure 6 Algebraic triangulation
Figure 6 Algebraic triangulation
This is a multi view approach which can use multiple cameras from different angles for more precise pose estimation. Here two solutions are presented to leverage information from multiple 2D views.
Algebraic triangulation
As shown in Figure 6 the RGB images are passed through a 2D CNN to extract the joints’ heatmaps and confidence score of joints for each camera. The joint keypoints are extracted by applying soft-argmax in the heatmaps. A linear algebraic triangulation method is used to extract 3d locations of joints. The triangulation algorithm assumes that the joint coordinates from each camera view are independent of each other. Because some joint cannot be precisely estimated from some view due to occlusions, the network uses learnable weights (fully connected layer) to control each camera’s contribution during the triangulation.
 Figure 7 Volumetric triangulation
Figure 7 Volumetric triangulation
Volumetric triangulation approach
The major difference here is that the feature maps are unprojected into 3D volumes. A fixed size 3D cube around the person is filled via projecting output of the 2D network along projection rays inside the 3D cube. The volumetric maps from all views are aggregated to and fed to V2V network. The V2V module is a 3D convolutional neural network that outputs 3D heatmaps. Soft argmax is uses in the 3D heatmaps to output the joint locations. This approach is currently the state-of-the art method in Human3.6M dataset, the largest dataset with human poses.
 Figure 8 Results from volumetric approach
Figure 8 Results from volumetric approach
Conclusion
We presented some of the most popular and recent works-advances in Human Pose Estimation. We can expect many more solutions as deep learning is still advancing and being applied in Computer Vision.
Also if you are interested in dive deep into Computer Vision with Deep Learning, there is no better way than the Advanced Computer Vision with TensorFlow course by DeepLearning.ai.
References
- Sarafianos, Nikolas & Boteanu, Bogdan & Ionescu, Bogdan & Kakadiaris, Ioannis. (2016). 3D Human Pose Estimation: A Review of the Literature and Analysis of Covariates. Computer Vision and Image Understanding. 152. 10.1016/j.cviu.2016.09.002.

* Disclosure: Please note that some of the links above might be affiliate links, and at no additional cost to you, we will earn a commission if you decide to make a purchase after clicking through.