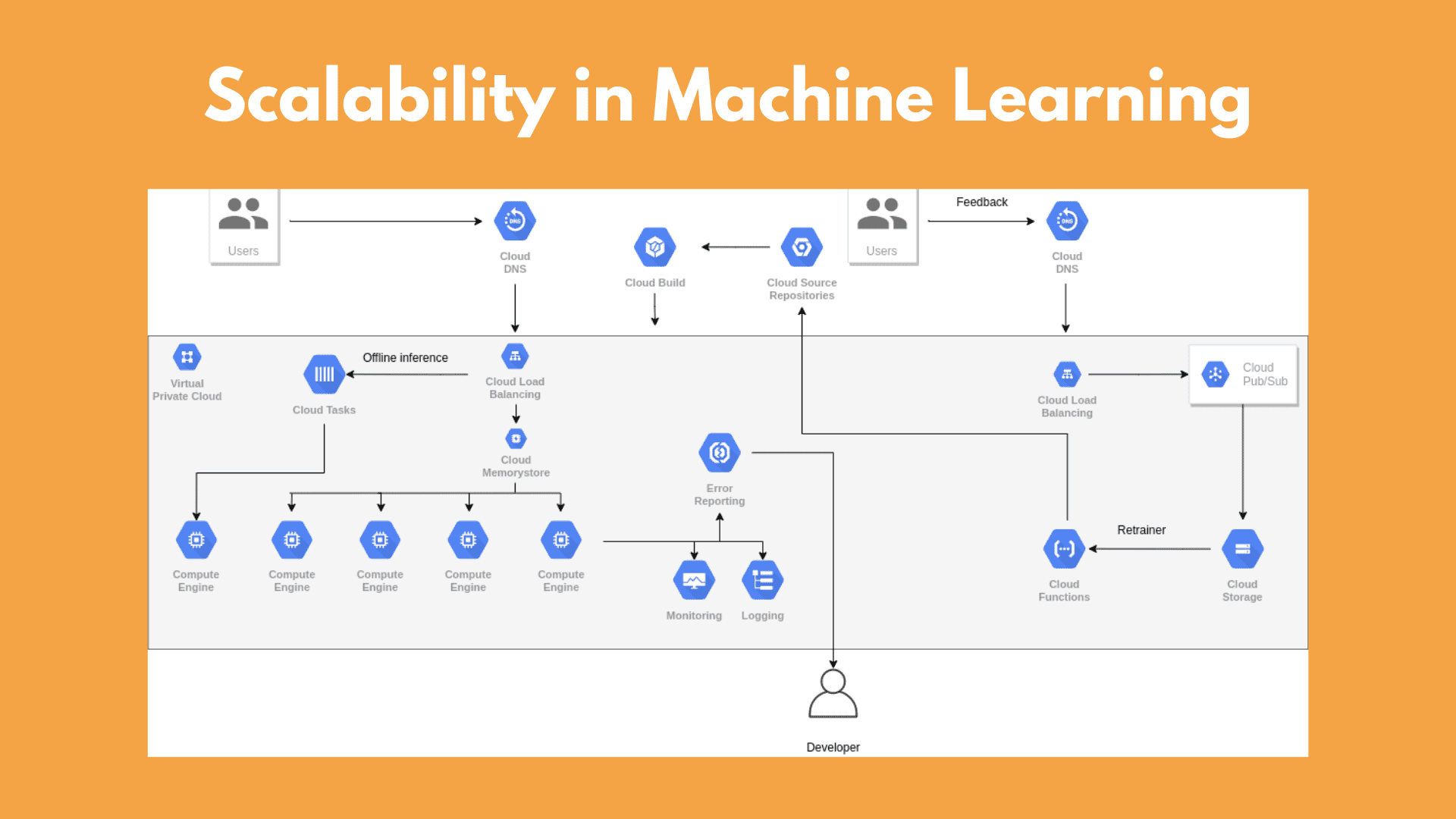
Scalability is certainly a high-level problem that we will all be thrilled to have. Reaching a point where we need to incorporate more machines and resources to handle the traffic coming into our deep learning algorithm, is a dream come true for many startups.
However many engineering teams don't pay the necessary attention to it. The main reason: they don't have a clear plan on how to scale things up from the beginning. And that's perfectly fine! Because we first need to focus on optimizing our application and our model, and deal with all that stuff later. But it wouldn’t hurt us to have a clear plan from the start.
In this article, we will follow along with a small AI startup on its journey to scale from 1 to millions of users. We will discuss what's a typical process to handle a steady growth in the user base, and what tools and techniques one can incorporate. And of course, we will explore scalability from a machine learning perspective. We will see how things differentiate from common software and what novel problems arise.
So let's imagine that we have a Deep Learning model that performs segmentation on an image. We train it, we optimize the data processing pipeline, we build a standard web application around it, and now it's time to deploy it.
So what is our next step here?
At this point, we have basically two options. The first is to set up our own server, host it there, and worry about all the scalability things as we grow. Preferably we can deploy the application in a cloud provider and take advantage of all the ready-to-use infrastructure. I will assume that you will go with the second option. If you choose the first one, I seriously would like to know why!
Let's say that we picked Google Cloud as our provider, we opened an account, set up a project and we're ready to go.
Shall we?
There is a great talk happening every year in the AWS conference where they present how to scale an application from 1 to 10 million users exploring all the different AWS systems that we can use along the process. This article is heavily inspired by it but it focuses on machine learning applications instead of plain software.
Note that I will use Google Cloud components to illustrate the different architectures but the same principles apply to other cloud computing services such as AWS or Azure. For those who are unfamiliar with Google Cloud Services (GCS), I’ll leave a glossary section at the end outlining the used components.

First deployment of the Machine Learning app
As we said in a previous article, a VM instance is nothing more than a dedicated computing system hosted on Google cloud.
The first step would be to create a VM instance on Google cloud’s compute engine. We copy the whole project, allow HTTP traffic, and connect our domain name to it. And that's it. The model is up and running and is visible to users through our domain. People are starting to send requests, everything works as expected, the system remains highly responsive, the model’s accuracy seems to be on good levels.
And we are incredibly happy about it.

So we have a monolithic app hosted in one virtual machine which requires a bit of manual work to deploy new changes and restart the service. But it’s not bad. After doing that for a few weeks however, some problems are starting to arise.
Deployments require too much manual work
Dependencies are starting to get out of sync as we add new library versions and new models
Debugging is not straightforward.
To solve some of those problems, we add a new CI/CD pipeline and we manage to automate things like building, testing, and deployment.
Continuous integration (CI) and Continuous deployment (CD) is a set of practices and pipelines that automates the building, testing, and deployment process. Famous frameworks include Jenkins and CircleCI but for example’s sake, we’ll use the Cloud Build component from GCS.
We also add some logs so we can access the instance and discover what’s wrong. Perhaps we can even migrate from a basic Virtual machine to a Deep Learning specific VM which is optimized for Deep Learning applications. It comes with Tensorflow, CUDA, and other necessary stuff preinstalled, helping us alleviate some of the manual work.

But deployment and dependencies are still an issue. So we wrap the application inside of a docker container, put it in the VM and we’re good to go. Again, we can use a ready-to-use Deep Learning specific container. As a result, every time we need to add a new library version or a new model, we change the Dockerfile, rebuild the container, and redeploy. Things are looking good once more.
After a while, the app is starting to become popular. More and more users are joining, and the VM instance is starting to struggle: response times go up, hardware utilization is at very high levels.
I'm afraid that we have to scale.
Vertical vs horizontal scaling
Vertical scaling (scaling-up) is when we add more power (CPU, Memory, GPU) to an existing machine to handle the traffic.
Our first reaction is to scale vertically. After a while, the instance is struggling again. We then create an even bigger one. After doing that a couple of times, we're starting to hit a limit and realize that we can’t keep scaling up.

Consequently, we have to scale out.
Horizontal scaling (scaling out) is when we add more machines to the network and share the processing and memory workload across them.
This simply means: create a new VM instance! We will then replicate the application and have them both run and serve traffic simultaneously.
But how do we decide which instance to send the requests to? How do we keep the traffic even between them? This is where load balancers come into the game.
A load balancer is a device that distributes network traffic across multiple machines and ensures that no single server bears too much load, by spreading the traffic. Therefore, it increases the capacity, reliability, and availability of the system.

After including a second instance and a load balancer, the traffic is handled perfectly. Neither instance is struggling and their response times go back down.
Scaling out
The great thing about this architecture is that it can take us a long way down the road. Honestly, it is probably what most of us will ever need. As traffic grows, we can keep adding more and more instances and load balance the traffic between them. We can also have instances in different geographic regions ( or availability zones as AWS calls them) to minimize the response time in all parts of the world.
Interesting fact: we don't have to worry about the load balancer! Because most cloud providers such as GCS offer load balancers that scale requests among multiple regions.

Load balancers also provide robust security. They entail encryption/decryption, user authentication, health connections checks. There also have capabilities for monitoring and debugging.
Recap
So far, we managed to ensure availability and reliability using load balancers and multiple instances. In parallel, we alleviate the pain of deployments with containers and CI/CD, and we have a basic form of logging and monitoring.
I’d say that we are in pretty good shape.
Again, in the vast majority of use cases, this architecture is 100% enough. But there are times when certain unpredictable things can occur. A very common example is sudden spikes in traffic.
Sometimes we may see very big increases in the incoming requests. Maybe it's Black Friday and people want to shop or we are in the middle of a lockdown and they all surf the web. And trust me it is more common than you may want to believe.
What’s the course of action here?
One might think that we can increase the capacity of our machines beforehand. In this way, we can handle the spikes in the request rate. But that would be a huge amount of unused resources. And most importantly: money not well spent.
The solution to such problems? Autoscaling.
Autoscaling
Autoscaling is a method used in cloud computing that alters the number of computational resources based on the load. Typically this means that the number of instances goes up or down automatically, based on some metrics.
Autoscaling comes into 2 main forms: scheduled scaling and dynamic scaling.
In scheduled scaling, we know in advance that the traffic will vary in a specific period of time. To tackle this, we manually instruct the system to create more instances during this time.
Dynamic scaling, on the other hand, monitors some predefined metrics and scales the instances when they surpass a limit. These metrics can include things like CPU or Memory utilization, requests count, response time, and more. For example, we can configure our number of instances to double when the number of requests is more than 100. When the requests fall again, the instances will go back to their normal state.
And that efficiently solves the random spikes issue. One more box checked for our application.
Caching
Another great way to minimize the response time of our application is to use some sort of caching mechanism. Sometimes we may see many identical requests coming in (although this rarely will be the case for computer vision apps). If that's the case, we can avoid hitting our instances many times and we can cache the response of the first request and send it to all the other users.
A cache is nothing more than a storage system that saves data so that future requests can be served faster
An important thing to know here is that we have to calibrate our caching mechanism efficiently in order to avoid two things: either caching too much data that will not be used frequently or keeping the cache idle for a very long time.

Monitoring alerts
One of the most important and honestly most annoying parts of an application that's been served to millions of users is alerts. Sometimes things crash. Maybe there was a bug in the code, or the auto-scaling system didn’t work, or there was a network failure, or some power outage occurs (there are literally 100 things that can go wrong). If our application serves only a few users, this might not be that critical. But in the case where we serve millions of them, every minute our app is down we're losing money.
That's why we must have an alerting system in place, so we can jump as quickly as possible and fix the error. Being on-call is an integral part of being a software engineer (in my own opinion is the worst part). This applies to machine learning engineers too. Although some of the time, in real-life projects that’s not the case. But machine learning models can have bugs as well and they are affected by all the aforementioned things.
No need to build a custom solution. Most cloud providers provide monitoring systems that 1) track various predefined metrics 2) enable visualizations and dashboards for us to check their progress over time and 3) notify us when an incident happens.

A monitoring system combined with logging and an error reporting module is all we need to sleep well at night. So I highly recommend incorporating such mechanisms in your machine learning application.
Up until this point of the article, most of the concepts mentioned apply to all kinds of software. That’s why from now on we will see some examples that are needed only for machine learning applications. Although the tools that we will use are not specific to ML, the concepts and the problems behind them are unique in the field.
We've put a lot of effort so far to keep the application scalable and I think we can say that we've done a pretty good job. And I dare to say that we might be able to scale to millions of users. But most machine learning applications have some other needs and problems to solve.
Retraining Machine Learning Models
As time passes and the model serves more and more users, the data distribution is starting to shift. As a result, the model’s accuracy is gradually falling down. It is simply inevitable and it happens to most machine learning applications. Thus, we need to build a loop to retrain the model with new data and redeploy it as a new version. We can find the data from an external source, but sometimes this isn't possible. That’s why we should be able to use internal data.
With our current architecture, this is not feasible as we don't store any predictions or feedback. First of all, we need to find a way to get back feedback from our users and use them as labels in our retraining. This means that we will need an endpoint that clients send their feedback related to a specific prediction.
If we assume that we have that in place, the next step is to store the data. We need a database. Here we have many solutions and it is a very common debate between teams. Most scalability experts will claim that we should start with a SQL database and move to a NoSQL when the audience grows to a specific point. Although this is true in 95% of the cases, someone could argue that machine learning is not one of them. Because machine learning data are unstructured and they can't be organized in the form of tables.

From a scalability perspective both SQL and NoSQL can handle a pretty big amount of data with NoSQL having a slight advantage in the area. I'm not gonna go into many details here about how scalability works on databases, but I will mention some basic concepts for those who want to look into them.
For SQL folks, we have techniques such as master-slave replication, sharding, denormalization, federation while for NoSQL the scalability patterns are custom to the specific database type (key-value, document, column-based, graph).
The crucial thing is that we now have the data stored. As a result, we can start building training jobs by feeding the persisted data into the model. The new model will be deployed into production replacing the old one. And we can repeat this process according to our needs.
Two things to note here:
The model versioning problem is already solved by containers because we can create a new image from the new model and deploy it.
The storage of the model weights is also solved. Either by using the database or preferably with an object storage service (such as google cloud storage) which can be extremely scalable and efficient.
However, the problem of running multiple, high-intensive, simultaneous jobs remains. As usual, we have different solutions.
We can spin up new instances/containers on demand, run the jobs, and remove them after completion.
We can also use a distributed data processing framework such as Hadoop or Spark. These frameworks are able to handle enormous amounts of data and scale efficiently across different machines.
Most big data processing frameworks are based on some form of the map-reduce paradigm. Map-reduce is a distributed algorithm that works as follows: We first acquire the data in many different chunks, execute a processing step on each one (one) and then combine the results into a single dataset (reduce). As you can imagine this method is highly scalable and it can handle big amounts of data.
 Source: A BIG DATA PROCESSING FRAMEWORK BASED ON MAPREDUCE WITH APPLICATION TO INTERNET OF THINGS
Source: A BIG DATA PROCESSING FRAMEWORK BASED ON MAPREDUCE WITH APPLICATION TO INTERNET OF THINGS
Model A/B testing
Another need that it might appear, especially after having retraining in place, is model A/B testing. A/B testing refers to the process of trying out different models in production by sending different loads of traffic into each one of them. Again, Docker solves this issue out of the box, because it enables us to deploy different containers at the same time. To distribute the traffic, we can configure the load balancer to send the requests accordingly. For example, we can send only 5% of the traffic into the new model and keep the other 95% for the old one.
Offline inference
Last but not least we have offline inferences. Predicting in real-time is not always feasible or desired. There are plenty of use cases when the model simply can't infer in a couple of seconds or our application does not need an immediate response. In those cases, the alternative is to have an offline inference pipeline and predict in an asynchronous manner.
Asynchronicity means that the user won't have to wait for the model’s response. He will be notified later about the completion of the prediction (or not notified at all). But how do we build such pipelines?
The most common approach is task/message queues.
A message queue is a form of asynchronous service to service communication. A queue stores messages coming from a producer and ensures that each one will be processed only once by a single consumer. A message queue can have multiple consumers and producers.
 Google cloud Pub/Sub. Source: enterpriseintegrationpatterns.com
Google cloud Pub/Sub. Source: enterpriseintegrationpatterns.com
In our case, a producer will be an instance that receives the inference request and sends it to a worker. The workers will execute the inference based on the sent features. Instead of sending the messages directly to the worker (aka the consumer), it will send it to a message queue. The message queue receives messages from different producers and sends them to different consumers. But why do we need a queue?
A few characteristics that make message queues ideal are:
They ensure that the message will always be consumed
They can be scaled almost effortlessly by adding more instances
They operate asynchronously
They decouple the consumer from the producer
They try to maintain the order of messages
They provide the ability to prioritize tasks.

An offline inference pipeline can be executed either in batches or one-by-one. In both cases, we can use message queues. However, in the case of batching, we should also have a system that combines many inferences together and send them back to the correct user. Batches can happen either on the instance level or on the service level.
And that officially ends our scalability journey. From now on, all we can do is fine-tune the application. Solutions include:
Splitting functionality into different services by building a microservices architecture
Analyzing in-depth the entire stack and optimizing wherever it’s possible.
As a last resort, we can start building custom solutions.
But by then, we will have at least 1 million dollars in revenue so things are looking good.
Wrap up
In this arguably long post, I tried to give an overview of how companies' infrastructure evolves over the years as they grow and acquire more users. Scaling an application is by any means an easy endeavor, and it becomes even more difficult for machine learning systems. The main reason is that they introduce a whole new set of problems that are not present in common software.
The fun part is that I didn't even begin to cover the entire spectrum of solutions and problems. But that would be impossible for a single article (or even a single book). I do also know that some may have difficulties grasping all the different systems and terminology. However, I hope that this post will act as a guide to help you understand the basics and go from there to explore and dive deep into the various architectures and techniques.
To continue from here, I strongly recommend the MLOps (Machine Learning Operations) Fundamentals course offered by Google cloud
Finally, it’s worth mentioning that this article is part of the deep learning in production series. So far, we took a simple Jupyter notebook, we converted it to highly performant code, we trained it, and now it's time to deploy it in the cloud and serve it to 2 users.
That's why I wanted to write this overview before we proceed with the deployment. So that we all can have a clear idea of what lies ahead in real-life projects. If you would like to follow along with the series, don't forget to subscribe to our newsletter. It's already the 13th article and I don't see us stopping anytime soon. Next time we will dive into Kubernetes so stay tuned…
Addio …
Glossary
- Compute engine: Enables users to launch and manage virtual machines on demand
- Virtual private cloud: Provides network functionality among GC resources
- Load balancing: Globally distributed load balancer
- Cloud memorystore: A managed in-memory service based on cache systems such as Redis and Memcached
- Cloud tasks: Distributed task queues for asynchronous execution
- Cloud DNS: DNS serving from Google’s worldwide network
- Cloud Build: CI/CD platform
- Cloud source repositories: Private git repositories
- Pub/Sub: Asynchronous messaging system
- Cloud functions: Serverless execution environment
- Cloud storage: Object storage system
- Monitoring: Provides visibility into the performance, uptime, and overall health of applications
- Cloud logging: Real-time log management and analysis
- Error reporting: Counts and aggregates crashes from services based on their stack traces.
* Disclosure: Please note that some of the links above might be affiliate links, and at no additional cost to you, we will earn a commission if you decide to make a purchase after clicking through.